I am running a pearson correlation on my data set (from Excel) and this is the order the results come out as:
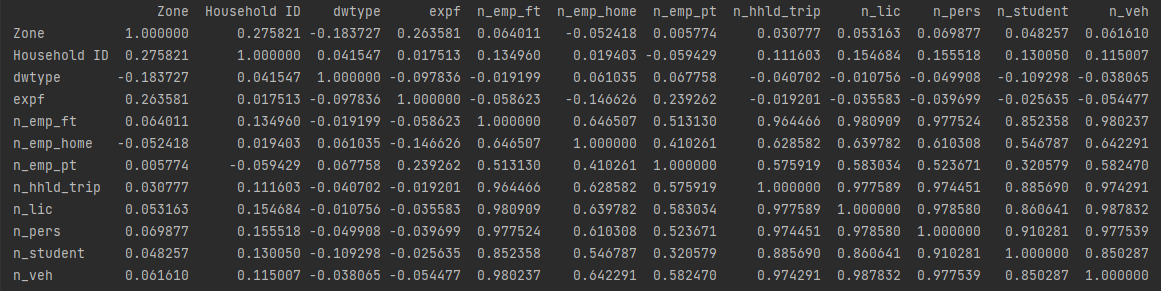
What I was wondering is if it is possible to get the n_hhld_trip as my first column as it is my dependent variable.
Below is my code that I have so far but not sure how to make it reflect the changes I want. I tried moving the variables in the pivot table command but that didn't do it:
zone_sum_mean_combo = pd.pivot_table(
read_excel,
index=['Zone'],
aggfunc={'Household ID': np.mean, 'dwtype': np.mean, 'n_hhld_trip': np.sum,
'expf': np.mean, 'n_emp_ft': np.sum, 'n_emp_home': np.sum,
'n_emp_pt': np.sum, 'n_lic': np.sum, 'n_pers': np.sum,
'n_student': np.sum, 'n_veh': np.sum}
)
index_reset = zone_sum_mean_combo.reset_index()
print(index_reset)
pearson_correlation = index_reset.corr(method='pearson')
print(pearson_correlation)
CodePudding user response:
Sometimes it can be easier to hardcode the column order after everything is done:
df = df[["my_first_column", "my_second_column"]]
In your case, I think it's easier to just manipulate them:
columns = list(df.columns)
columns.remove("n_hhld_trip")
columns.insert(0, "n_hhld_trip")
df = df[columns]
CodePudding user response:
Try to set_index and reset_index:
df.set_index('n_hhld_trip', append=True).reset_index(level=-1)