I am working with the R programming language. I have a dataset which contains a person's height and whether or not they play basketball.
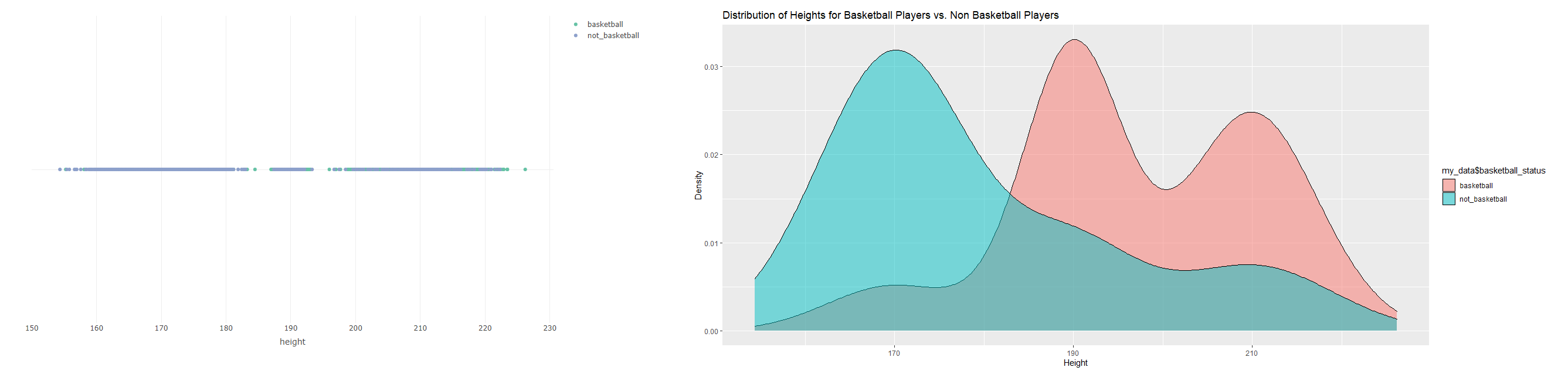
I want to see if on average, people over the 80th percentile (height wise) play basketball.
To do this, I:
- I randomly break the data into a 70% group (train) and a 30% group (test)
- I calculate the 80th percentile of the train group: using this 80th percentile, I see how many people in the test group play basketball
- I calculate on average how accurate I was (on the test group)
- I repeat this procedure many times (e.g. 100) and calculate the total average.
Here is the R code that generates the data for this example:
set.seed(123)
height <- rnorm(1000,210,5)
status <- c("basketball", "not_basketball")
basketball_status <- as.character(sample(status, 1000, replace=TRUE, prob=c(0.80, 0.20)))
data_1 <- data.frame(height, basketball_status)
height <- rnorm(1000,190,1)
status <- c("basketball", "not_basketball")
basketball_status <- as.character(sample(status, 1000, replace=TRUE, prob=c(0.8, 0.2)))
data_2 <- data.frame(height, basketball_status)
height <- rnorm(1000,170,5)
status <- c("basketball", "not_basketball")
basketball_status <- as.character(sample(status, 1000, replace=TRUE, prob=c(0.20, 0.80)))
data_3 <- data.frame(height, basketball_status)
my_data <- rbind(data_1, data_2, data_3)
And here is the iterative process:
library(dplyr)
results <- list()
for (i in 1:100) {
train_i<-sample_frac(my_data, 0.7)
sid<-as.numeric(rownames(train_i))
test_i<-my_data[-sid,]
quantiles = data.frame( train_i %>% summarise (quant_1 = quantile(height, 0.80)))
test_i$basketball_pred = as.character(ifelse(test_i$height > quantiles$quant_1 , "basketball", "not_basketball" ))
test_i$accuracy = ifelse(test_i$basketball_pred == test_i$basketball_status, 1, 0)
results_tmp = data.frame(test_i %>%
dplyr::summarize(Mean = mean(accuracy, na.rm=TRUE)))
results_tmp$iteration = i
results_tmp$total_mean = mean(test_i$accuracy)
results[[i]] <- results_tmp
}
results
results_df <- do.call(rbind.data.frame, results)
But when I run the iterative process, all averages appear the same:
head(results_df)
Mean iteration total_mean
1 0.8344444 1 0.8344444
2 0.8344444 2 0.8344444
3 0.8344444 3 0.8344444
4 0.8344444 4 0.8344444
5 0.8344444 5 0.8344444
6 0.8344444 6 0.8344444
Question: Does anyone know why this is happening?
Thanks
CodePudding user response:
sid<-as.numeric(rownames(train_i)) is not doing what you expect, I think. You are probably looking to identify which of the original data frame rows are being included in the preceding line train_i<-sample_frac(my_data, 0.7), but it's actually just outputting 1:2100, so that all the steps later on provide identical results each time.
I think if you replace those lines with:
my_data$row = 1:nrow(my_data)
train_i <- sample_frac(my_data, 0.7)
sid <- train_i$row
you'll get results like you're expecting.
Mean iteration total_mean
1 0.5111111 1 0.5111111
2 0.5244444 2 0.5244444
3 0.5177778 3 0.5177778
4 0.5488889 4 0.5488889
5 0.5322222 5 0.5322222
Full code that works for me:
results <- list()
for (i in 1:100) {
my_data$row = 1:nrow(my_data)
train_i<-sample_frac(my_data, 0.7)
sid<-train_i$row
test_i<-my_data[-sid,]
quantiles = data.frame( train_i %>% summarise (quant_1 = quantile(height, 0.80)))
test_i$basketball_pred = ifelse(test_i$height > quantiles$quant_1 , "basketball", "not_basketball" )
test_i$accuracy = ifelse(test_i$basketball_pred == test_i$basketball_status, 1, 0)
results_tmp = data.frame(test_i %>%
dplyr::summarize(Mean = mean(accuracy, na.rm=TRUE)))
results_tmp$iteration = i
results_tmp$total_mean = mean(test_i$accuracy)
results[[i]] <- results_tmp
}
CodePudding user response:
Not an answer - using the answer kindly provided by @ Jon Spring:
results <- list()
for (i in 1:100) {
my_data$row = 1:nrow(my_data)
train_i <- sample_frac(my_data, 0.7)
sid <- train_i$row
quantiles = data.frame( train_i %>% summarise (quant_1 = quantile(height, 0.80)))
test_i$basketball_pred = as.character(ifelse(test_i$height > quantiles$quant_1 , "basketball", "not_basketball" ))
test_i$accuracy = ifelse(test_i$basketball_pred == test_i$basketball_status, 1, 0)
results_tmp = data.frame(test_i %>%
dplyr::summarize(Mean = mean(accuracy, na.rm=TRUE)))
results_tmp$iteration = i
results_tmp$total_mean = mean(test_i$accuracy)
results[[i]] <- results_tmp
}
results
results_df <- do.call(rbind.data.frame, results)
Here is the final answer:
head(results_df)
Mean iteration total_mean
1 0.8344444 1 0.8344444
2 0.8344444 2 0.8344444
3 0.8344444 3 0.8344444
4 0.8344444 4 0.8344444
5 0.8344444 5 0.8344444
6 0.8344444 6 0.8344444
@Jon Spring: The numbers are still the same? Did I understand your answer correctly?
Thank you so much for all your help!