I have a dataframe like:
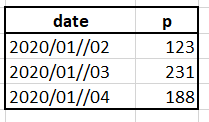
so I want add some columns by two "for loop" like:
new dataframe like picture:
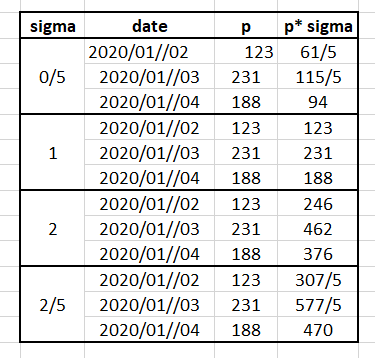
my code does not work:
for I in range(0,len(df["date"]):
for sigma in rang(1,2/5):
df["P*sigma"].iloc[0:i]=df["p"].iloc[0:i]*df["sigma"].iloc[sigma]
print(df)
how do I write code to obtain the dataframe like second picture?
CodePudding user response:
You can do this with a MultiIndex, which can be done in various ways, but I always prefer using from_product().
Note that we will have to do some preparation before we can do this. We have to make sure the index is properly set on the original DataFrame, and we have to elongate the original DataFrame to allow the new rows.
import pandas as pd
df = pd.DataFrame({'date': ['2020/01/01', '2020/01/02', '2020/01/03'], 'p': [123, 231, 188]})
df = df.set_index('date')
sigma = [0, 1, 2, 5]
# Create new 2-level index
multi_index = pd.MultiIndex.from_product([sigma, df.index], names=['sigma', 'date'])
# Make longer
df = pd.concat([df] * len(sigma))
# Set new index
df = df.set_index(multi_index)
# Print result
print(df.head())
>>> p
>>> sigma p
>>> 0 2020/01/01 123
>>> 2020/01/02 231
>>> 2020/01/03 188
>>> 1 2020/01/01 123
>>> 2020/01/02 231
If you want to make new columns or use the index values, you can get those with get_level_values() like this:
df["p*sigma"] = df.index.get_level_values("sigma") * df["p"]
print(df.head())
>>> p p*sigma
>>> sigma date
>>> 0 2020/01/01 123 0
>>> 2020/01/02 231 0
>>> 2020/01/03 188 0
>>> 1 2020/01/01 123 123
CodePudding user response:
After adding rows and column "sigma" like this You can use DataFrame.apply like
df["P*sigma"] = df.apply(lambda x: x["p"] * x["sigma"], axis=1)
CodePudding user response:
In python you can repeate an array using the mulipliciation sign *. If you have the free columns sigma, date and p it is easy to define a DataFrame in the correct shape. To create the new column just do an element wise multiplication (there is no need for an apply() call. Afterwards you can set the index, if wanted.
import pandas as pd
sigma = [0.5, 1, 2, 2/5]
date = ['2020/01//02', '2020/01//03', '2020/01//04']
p = [123,231,188]
df = pd.DataFrame({'sigma':sigma*len(p), 'date':date*len(sigma), 'p':p*len(sigma)})
df['p*sigma'] = df['p']*df['sigma']
df.set_index(['sigma', 'date'], inplace=True)
>>>df
p p*sigma
sigma date
0.5 2020/01//02 123 61.5
1.0 2020/01//03 231 231.0
2.0 2020/01//04 188 376.0
0.4 2020/01//02 123 49.2
0.5 2020/01//03 231 115.5
...