I wish to achieve the following:
For each Group, when the ID column is NA, then fill the corresponding NA value in Name with the concatenation of the other values of Name while ignoring other NA values in Name
My data frame looks as follows:
x <- data.frame(Group = c("A","A","A","A","B","B"),ID = c(1,2,3,NA,NA,5),Name = c("Bob","Jane",NA,NA,NA,"Tim"))
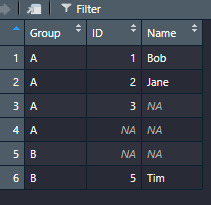
This is what I wish to achieve:
y <- data.frame(Group = c("A","A","A","A","B","B"),ID = c(1,2,3,NA,NA,5),Name = c("Bob","Jane",NA,"Bob Jane","Tim","Tim"))
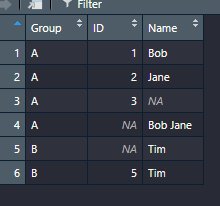
If there's a way to achieve this in the tidyverse I would be very grateful for any pointers.
I've tried the following but it doesn't find the object 'Name'
x %>% group_by(Group) %>% replace_na(list(Name = paste(unique(.Name))))
CodePudding user response:
We may use a conditional expression with replace
library(dplyr)
library(stringr)
x %>%
group_by(Group) %>%
mutate(Name = replace(Name, is.na(ID), str_c(Name[!is.na(Name)],
collapse = ' '))) %>%
ungroup
-output
# A tibble: 6 × 3
Group ID Name
<chr> <dbl> <chr>
1 A 1 Bob
2 A 2 Jane
3 A 3 <NA>
4 A NA Bob Jane
5 B NA Tim
6 B 5 Tim
CodePudding user response:
Does this work:
library(dplyr)
x %>% group_by(Group) %>%
mutate(Name = case_when(is.na(ID) ~ paste(Name[!is.na(Name)], collapse = ' '), TRUE ~ Name))
# A tibble: 6 x 3
# Groups: Group [2]
Group ID Name
<chr> <dbl> <chr>
1 A 1 Bob
2 A 2 Jane
3 A 3 NA
4 A NA Bob Jane
5 B NA Tim
6 B 5 Tim