I want to get the number of unique connections between locations, so a->b and b->a, should count as one. The dataframe contains timestamps and start&end location name. The result should present unique connections between stations per day of the year.
import findspark
findspark.init('/home/[user_name]/spark-3.1.2-bin-hadoop3.2')
import pyspark
from pyspark.sql.functions import date_format, countDistinct, struct, col
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('cluster1').getOrCreate()
from pyspark.sql.types import StructType,StructField, StringType, IntegerType, DateType, TimestampType
from pyspark.sql.functions import to_timestamp
data2 = [
('2017-12-29 16:57:39.6540','2017-12-29 16:57:39.6540',"A","B"),
("2017-12-29 16:57:39.6540","2017-12-29 17:57:39.6540","B","A"),
("2017-12-29 16:57:39.6540","2017-12-29 19:57:39.6540","B","A"),
("2017-12-30 16:57:39.6540","2017-12-30 16:57:39.6540","C","A"),
("2017-12-30 16:57:39.6540","2017-12-30 17:57:39.6540","B","F"),
("2017-12-31 16:57:39.6540","2017-12-31 16:57:39.6540","C","A"),
("2017-12-31 16:57:39.6540","2017-12-31 17:57:39.6540","A","C"),
("2017-12-31 16:57:39.6540","2017-12-31 17:57:39.6540","B","C"),
("2017-12-31 16:57:39.6540","2017-12-31 17:57:39.6540","A","B"),
]
schema = StructType([ \
StructField("start",StringType(),True), \
StructField("end",StringType(),True), \
StructField("start_loc",StringType(),True), \
StructField("end_loc", StringType(), True)
])
df2 = spark.createDataFrame(data=data2,schema=schema)
df2 = df2.withColumn("start_timestamp",to_timestamp("start"))
df2 = df2.withColumn("end_timestamp",to_timestamp("end"))
df2 = df2.drop("start", "end")
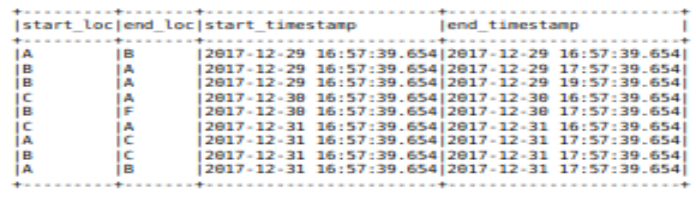
df2.printSchema()
df2.show(truncate=False)
df2_agg = df2.withColumn("date", date_format('start_timestamp', 'D'))\
.groupBy('date', 'start_loc','end_loc').agg(
collect_list(struct(col('start_loc'), col('end_loc'))).alias("n_routes_sets"),
)
df2_agg.show()
The result looks like this:
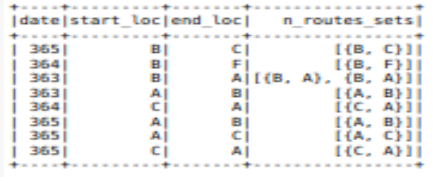
,but the Result should be like this:
| date | n_routes |
|---|---|
| 365 | 3 |
| 364 | 2 |
| 363 | 1 |
Below line is wrong.
collect_list(struct(col('start_loc'), col('end_loc'))).alias("n_routes_sets"),
CodePudding user response:
Modify your lines as per below and reorder the a,b and b,a always as a,b or vice-versa:
from pyspark.sql.functions import date_format, countDistinct, collect_set, struct, col, when, size
...
...
df2 = df2.withColumn("sl2", when(df2['end_loc'] < df2['start_loc'], df2['end_loc']).otherwise(df2['start_loc']) )
df2 = df2.withColumn("el2", when(df2['end_loc'] > df2['start_loc'], df2['end_loc']).otherwise(df2['start_loc']) )
df2 = df2.drop("start_loc", "end_loc")
df2.printSchema()
df2.show(truncate=False)
df2_agg = df2.withColumn("date", date_format('start_timestamp', 'D'))\
.groupBy('date').agg(collect_set(struct(col('sl2'), col('el2'))).alias("n_routes_sets"),
)
df2_agg.select("date", size("n_routes_sets")).show()
returns:
---- -------------------
|date|size(n_routes_sets)|
---- -------------------
| 363| 1|
| 364| 2|
| 365| 3|
---- -------------------