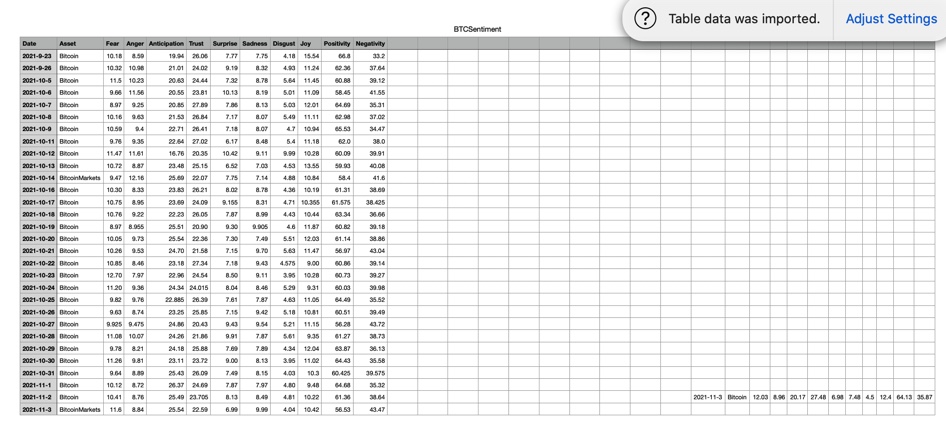
I have a function that writes a set of information in rows to a CSV file in Python. The function is supposed to append the file with the new row, however I am finding that sometimes it misbehaves and places the new row in a separate space of the CSV (please see picture as an example).
Whenever I reformat the data manually I delete all of the empty cells again, so you know.
Hoping someone can help, thanks!
def Logger():
fileName = myDict[Sub]
with open(fileName, 'a ', newline="") as file:
writer = csv.writer(file)
if file.tell() == 0:
writer.writerow(["Date", "Asset", "Fear", "Anger", "Anticipation", "Trust", "Surprise", "Sadness", "Disgust", "Joy",
"Positivity", "Negativity"])
writer.writerow([date, Sub, fear, anger, anticip, trust, surprise, sadness, disgust, joy, positivity, negativity])
CodePudding user response:
Try this instead...
def Logger(col_one, col_two):
fileName = 'data.csv'
with open(fileName, 'a ') as file:
writer = csv.writer(file)
file.seek(0)
if file.read().strip() == '':
writer.writerow(["Date", "Asset"])
writer.writerow([col_one, col_two])
CodePudding user response:
At first I thought it was a simple matter of there not being a trailing newline, and the new row being appended on the same line, right after the last row, but I can see what looks like a row's worth of empty columns between them.
This whole appending thing looks tricky. If you don't have to use Python, and can use a command-line tool instead, I recommend GoCSV.
Here's a sample file based on your screenshot I mocked up:
base.csv
Date,Asset,Fear,Anger,Anticipation,Trust,Surprise,Sadness,Disgust,Joy,Positivity,Negativity
Nov 1,5088,0.84,0.58,0.73,1.0,0.26,0.89,0.22,0.5,0.69,0.59
Nov 2,4580,0.0,0.88,0.7,0.71,0.57,0.78,0.2,0.22,0.21,0.17
Nov 3,2469,0.72,0.4,0.66,0.53,0.65,0.64,0.67,0.78,0.54,0.32,,,,,,,
I'm calling it base because it's the file that will be growing, and you can see it's got a problem on the last line: all those extras commas (I don't know how they got there