Please can anyone help me, I am very new to Beautiful Soup for scraping web pages. I want to extract the first table on the webpage, however the table has irregular columns as shown in the attached image. The first 3 rows/ 3 columns is followed by a row with 1 column. Please note the first three rows can change in the future to be more or less than 3 rows. The single row/1 column is followed by some rows and 4 columns then a single row/column. Is there a way I can write the Beautiful Soup python script to extract the first 3 rows before the td tag with a columnspan of 6 then extract the next rows after the td tag with a columnspan of 6?
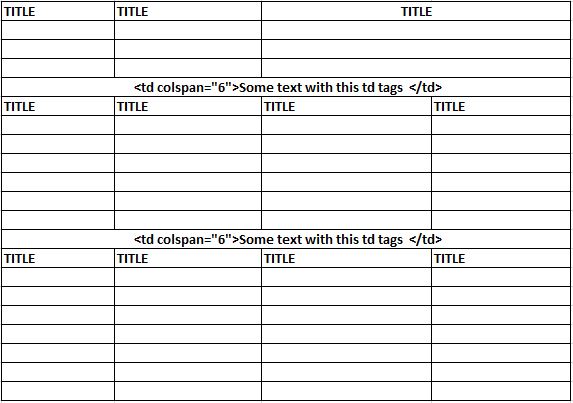
My Python code so far (#### gives me the entire table with the irregular column but not what I want):
import pandas as pd
import numpy as np
import requests
from bs4 import BeautifulSoup
url = " "
page = requests.get(url)
soup = BeautifulSoup(page.text, 'html.parser')
rows = []
for child in soup.find_all('table')[1].children:
row = []
for td in child:
try:
row.append(td.text.replace('\n', ''))
except:
continue
if len(row) > 0:
rows.append(row)
pd.DataFrame(rows[1:])
CodePudding user response:
Once having the table element I would select for the tr children not having a td with colspan = 6
Here is an example with colspan 3
from bs4 import BeautifulSoup as bs
html = '''<table id="foo">
<tbody>
<tr>
<th>A</th>
<th>B</th>
<th>C</th>
</tr>
<tr>
<td>D</td>
<td>E</td>
<td>F</td>
</tr>
<tr>
<td colspan="3">I'm not invited to the party :-(</td>
</tr>
<tr>
<td>G</td>
<td>H</td>
<td>I</td>
</tr>
</tbody>
</table>'''
soup = bs(html, 'lxml')
for tr in soup.select('#foo tr:not(:has(td[colspan="3"]))'):
print([child.text for child in tr.select('th, td')])