My code is something like this:
for i in uniqueProduct_list:
s3_df = channel_Result_8_df.filter((f.col("product") == i.product) & (f.col("S") == 3))
s3_list = s3_df.rdd.map(lambda x: x).collect()
for j in month_list:
print(s3_list[0].Gender)
break
break
This code is working fine when in line 5 I have a fixed column name, However, when I am trying to replace this with another column name whose name is not fixed e.g. 202005 (this column name keep changing and I am accessing it through another list (month_list, in line 4), so I am changing my code like this (only line 5 is changed):
for i in uniqueProduct_list:
s3_df = channel_Result_8_df.filter((f.col("product") == i.product) & (f.col("S") == 3))
s3_list = s3_df.rdd.map(lambda x: x).collect()
for j in month_list:
print(s3_list[0].j.Month)
break
break
How this is giving me error. Can someone please tell how to access the column whose name is not fixed. Thanks in advance!
s3_list output looks like: [Row(product='xxxxx-xxxx', Gender='F', 202005=0, 202006=-1, 202007=2149)] and j.Month values are ['202005', '202006', '202007']
Dataframe looks like:
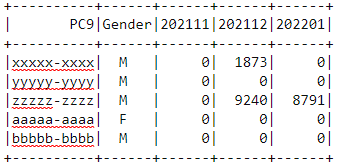
Also sample values of months is shown in dataframe.
CodePudding user response:
You can access the values of a Row using [] notation.
from pyspark.sql.types import *
from pyspark.sql import Row
schema = StructType([StructField('Product', StringType()), StructField('Gender',StringType()), StructField('202111',IntegerType()), StructField('202112',IntegerType()), StructField('202201',IntegerType())])
rows = [Row('xxxxx-xxxx', 'M', 0, 1873, 0)]
df = spark.createDataFrame(rows, schema)
s3_list = df.collect()
for m in ["202111", "202112", "202201"]:
print(s3_list[0][m])
CodePudding user response:
Replacing line 5 with s3_list[0].__getitem__(str(j.Month)) is working