I use scrapy + xpath, can take to include labels of the text between the text and the href attribute in the tag,
But the two label text, hope to give to solve once,
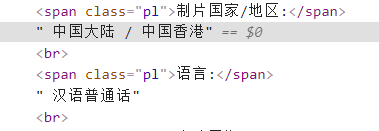
I want to crawl "China/Hong Kong, China",
CodePudding user response:
Python, why not try the beautifulsoup, rather easy to use, you can refer to my blog https://blog.csdn.net/qq_40832960/article/details/103854145CodePudding user response:
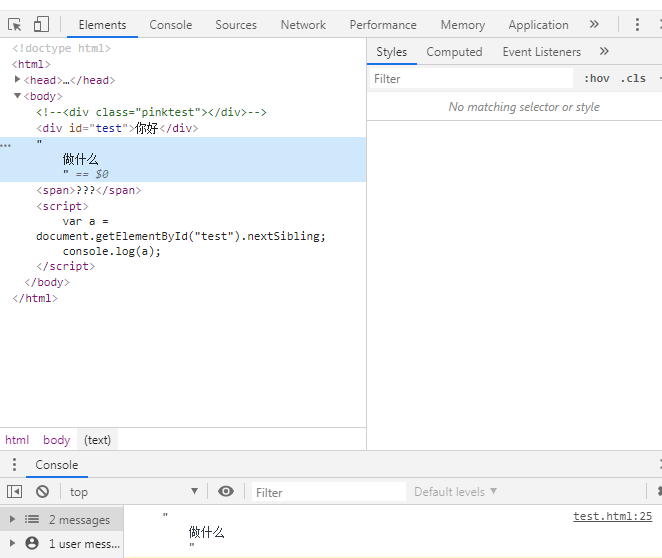
Were not retrieved dom element types, access to the document. The getElementsByClassName (" p1 "). NextSibling; Not to go