I am making a bar plot with ggplot2. For some reason the font created using geom_text looks very different than the rest. It looks 'worse', sort of pixely, and when I paste the pdf in a ppt presenation you can hardly read the geom_text text. The axis fonts look great.
Any help appreciated,
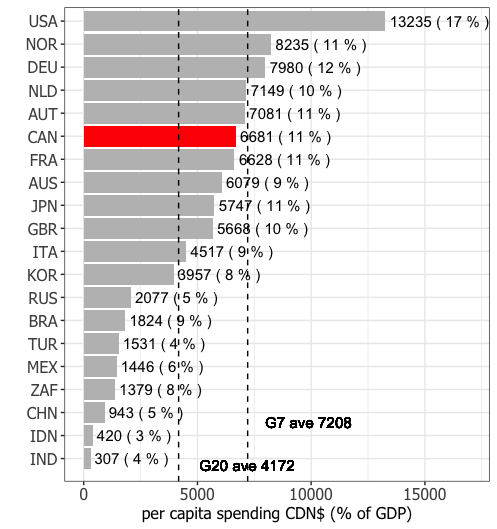
ggplot(OECD_CDNpercap_tot_aveplsGDP_select, aes(x=Country,mean, y=mean,
label=paste(round(mean),"(",round(mean_GDPP),"% )")))
geom_col(stat='identity', aes(fill=Can))
geom_hline(yintercept=G20_mean,linetype="dashed")
geom_hline(yintercept=G7_mean,linetype="dashed")
scale_fill_manual(values=c("red","grey"))
geom_text(color="black",size=4,hjust=-0.05) #hjust
geom_text(aes(0,G20_mean,label =paste("G20 ave",round(G20_mean))), size=4,vjust=-1,hjust=-0.22)
geom_text(aes(0,G7_mean,label =paste("G7 ave",round(G7_mean))), size=4,vjust=-5,hjust=-0.2)
labs(fill="Country")
ylab("per capita spending CDN$ (% of GDP)")
ylim(0,17000)
xlab("")
coord_flip()
guides(fill=FALSE)
theme_bw()
theme(axis.text = element_text(size = 12),axis.title = element_text(size = 12))
Here is my data if you want.
dput(OECD_CDNpercap_tot_aveplsGDP_select)
structure(list(Country = structure(1:20, .Label = c("IND", "IDN",
"CHN", "ZAF", "MEX", "TUR", "BRA", "RUS", "KOR", "ITA", "GBR",
"JPN", "AUS", "FRA", "CAN", "AUT", "NLD", "DEU", "NOR", "USA",
"BEL", "BGR", "CHE", "CHL", "COL", "CRI", "CYP", "CZE", "DNK",
"ESP", "EST", "FIN", "GRC", "HRV", "HUN", "IRL", "ISL", "ISR",
"LTU", "LUX", "LVA", "MLT", "NZL", "POL", "PRT", "ROU", "SVK",
"SVN", "SWE"), class = "factor", scores = structure(c(AUS = 6078.94112,
AUT = 7080.932352, BEL = NA, BGR = NA, BRA = 1824.00608, CAN = 6681.30592,
CHE = NA, CHL = NA, CHN = 942.641493333333, COL = NA, CRI = NA,
CYP = NA, CZE = NA, DEU = 7979.544064, DNK = NA, ESP = NA, EST = NA,
FIN = NA, FRA = 6628.256256, GBR = 5668.214272, GRC = NA, HRV = NA,
HUN = NA, IDN = 419.776426666667, IND = 307.127466666667, IRL = NA,
ISL = NA, ISR = NA, ITA = 4517.1136, JPN = 5746.82912, KOR = 3957.469696,
LTU = NA, LUX = NA, LVA = NA, MEX = 1446.171136, MLT = NA, NLD = 7148.905472,
NOR = 8235.11424, NZL = NA, POL = NA, PRT = NA, ROU = NA, RUS = 2077.27328,
SVK = NA, SVN = NA, SWE = NA, TUR = 1531.34976, USA = 13235.32544,
ZAF = 1379.19018666667), .Dim = 49L, .Dimnames = list(c("AUS",
"AUT", "BEL", "BGR", "BRA", "CAN", "CHE", "CHL", "CHN", "COL",
"CRI", "CYP", "CZE", "DEU", "DNK", "ESP", "EST", "FIN", "FRA",
"GBR", "GRC", "HRV", "HUN", "IDN", "IND", "IRL", "ISL", "ISR",
"ITA", "JPN", "KOR", "LTU", "LUX", "LVA", "MEX", "MLT", "NLD",
"NOR", "NZL", "POL", "PRT", "ROU", "RUS", "SVK", "SVN", "SWE",
"TUR", "USA", "ZAF")))), mean = c(307.127466666667, 419.776426666667,
942.641493333333, 1379.19018666667, 1446.171136, 1531.34976,
1824.00608, 2077.27328, 3957.469696, 4517.1136, 5668.214272,
5746.82912, 6078.94112, 6628.256256, 6681.30592, 7080.932352,
7148.905472, 7979.544064, 8235.11424, 13235.32544), Zscore = c(-1.54822118053674,
-1.50473107011314, -1.30286982358256, -1.13433252968883, -1.10847335724034,
-1.07558865272562, -0.962603537967679, -0.864825285113195, -0.138942420771726,
0.0771179421721642, 0.521520583208126, 0.551871226662394, 0.680088899981358,
0.892161660546499, 0.912642415497939, 1.06692522162298, 1.09316743899131,
1.41385006303133, 1.51251742023745, 3.4429368154036), fold = c(0.0711377750880183,
0.0972298614368974, 0.218337419538447, 0.31945212314462, 0.33496644936419,
0.354695774983234, 0.422481700143886, 0.481144200461144, 0.916640872948179,
1.04626725447706, 1.31288860748446, 1.33109761183142, 1.40802237866015,
1.53525638029903, 1.54754390087505, 1.64010656076147, 1.65585069649466,
1.84824567170948, 1.90744159416087, 3.06560534811859), Can = c("No",
"No", "No", "No", "No", "No", "No", "No", "No", "No", "No", "No",
"No", "No", "CAN", "No", "No", "No", "No", "No"), G7 = c("No",
"No", "No", "No", "No", "No", "No", "No", "No", "G7", "G7", "G7",
"No", "G7", "G7", "No", "No", "G7", "No", "G7"), G20 = c("G20",
"G20", "G20", "G20", "G20", "G20", "G20", "G20", "G20", "G20",
"G20", "G20", "G20", "G20", "G20", "No", "No", "G20", "No", "G20"
), mean_GDPP = c(3.56866666666667, 2.94066666666667, 5.05733333333333,
8.154, 5.6068, 4.23325, 9.424, 5.393, 7.619, 8.8926, 10.4986,
10.8985, 9.272, 11.4984, 10.877, 10.5974, 10.3634, 11.6484, 10.5592,
16.776)), row.names = c(NA, -20L), class = c("tbl_df", "tbl",
"data.frame"))
CodePudding user response:
It is overplotted for each row in your data. Set check_overlap = TRUE inside geom_text(), or use annotate instead. Or create a separate data frame for this layer with one row per label.