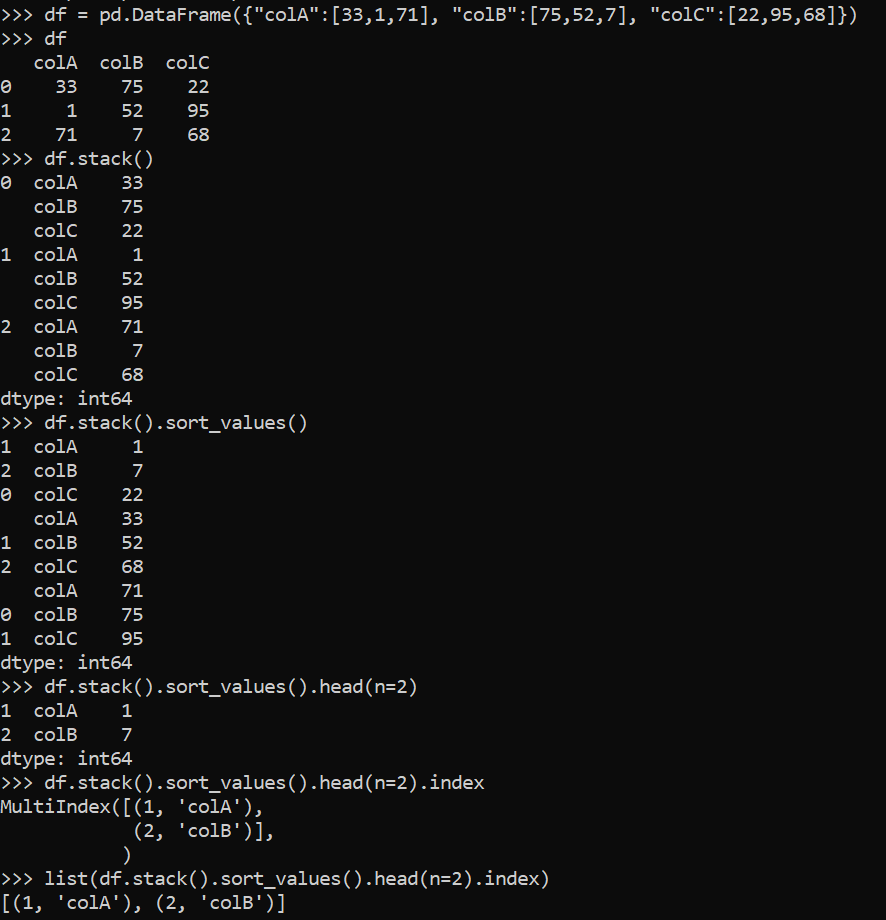
I'm searching for an efficient way to extract the indices of the n smallest values over the whole data frame.
For example, given the following df with n = 2:
colA colB colC
r1 33 75 22
r2 1 52 95
r3 71 7 68
I would like to get, in some form, the indices [(r2, colA), (r3, colB)] corresponding to the 2 smallest values over the whole df: 1 and 7.
The order between the indices is not important (The corresponding values may not be sorted).
Thanks!
CodePudding user response:
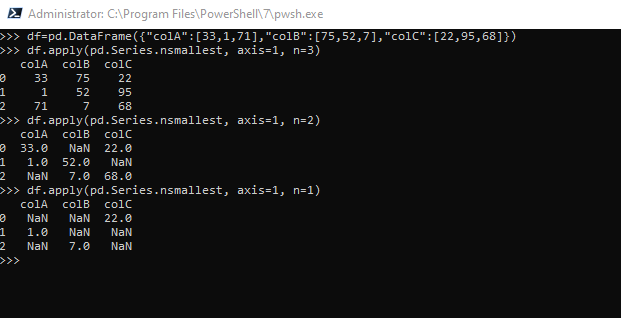
nsmallest -
CodePudding user response:
In addition to Neo's answer, in the meanwhile, I found the following solution:
n=2
list(df.stack().sort_values().head(n).index[])