I'm trying to generate a new dataframe that takes a certain total order and splitting it into actually shippable orders. Max eligibility shows what the maximum number of pallets can be put on an order. So in the below example, a total pallet order of 50, with a max eligibility 24, then I'd like the new dataframe to show the three orders as separate rows with 24, 24 and 2 (adds up to 50).
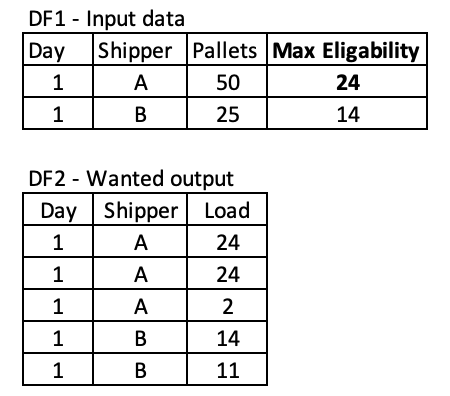
Code for the example dataframe:
df_input = pd.DataFrame({'date':['2021-12-01','2021-12-01','2021-12-02','2021-12-02'],
'shipper_id':['S1', 'S2','S1', 'S2'],
'pallets':[50, 25, 75, 15],
'max_eligability':[24, 14, 24, 14]
})
My first idea was to create a function that could repeat the full orders into one cell and then add the extra pallets in the end. Then explode the data using pandas .explode function.
def planned_routes(df):
df['full_orders'] = df['pallets'] // df['max_eligibility'] # get the total amount of full vans/orders
df['extra_pallets'] = df['pallets'] % df['max_eligibility']
df['order_splits'] = df['max_eligibility'].repeat(df['full_orders']), df['extra_pallets']
df = df.explode('order_splits')
df.drop(['pallets', 'max_eligibility','full_orders','extra_pallets'], axis=1, inplace=True)
return df
This approach gives errors in terms of indexing, which I speculate is because I'm trying to explode it without an corresponding index. I'm unsure how to solve this error.
Is there a more efficient solution to this rather than exploding the dataframe? Like a lambda function I'm missing to be able to generate new rows?
/ Olle
CodePudding user response:
Apply a function f to construct the data of a new dataframe:
def f(x):
q = x.pallets // x.max_eligability
r = x.pallets % x.max_eligability
l = [x.max_eligability] * q [r] * (1 if r else 0)
l = [(x.date, x.shipper_id, v, x.max_eligability) for v in l]
return l
df_output = pd.DataFrame(columns=df_input.columns,
data=[j for i in df_input.apply(f, axis=1) for j in i])
Output:
date shipper_id pallets max_eligability
0 2021-12-01 S1 24 24
1 2021-12-01 S1 24 24
2 2021-12-01 S1 2 24
3 2021-12-01 S2 14 14
4 2021-12-01 S2 11 14
5 2021-12-02 S1 24 24
6 2021-12-02 S1 24 24
7 2021-12-02 S1 24 24
8 2021-12-02 S1 3 24
9 2021-12-02 S2 14 14
10 2021-12-02 S2 1 14
CodePudding user response:
You could define a function that turns a given pair of total order size and maximum unit size values into a list of the individual sizes. Then apply that function to the two relevant columns to create a column of those lists. Finally, explode the dataframe on that list column:
def list_loads(value_pair):
total, max_size = value_pair[0], value_pair[1]
n_full, remainder = divmod(total, max_size)
result = n_full * [max_size]
if remainder > 0:
result.append(remainder)
return result
df = df_input[['date', 'shipper_id']].copy()
df['Load'] = df_input[['pallets', 'max_eligability']].apply(list_loads, axis=1)
df = df.explode('Load').reset_index(drop=True)
df
date shipper_id Load
0 2021-12-01 S1 24
1 2021-12-01 S1 24
2 2021-12-01 S1 2
3 2021-12-01 S2 14
4 2021-12-01 S2 11
5 2021-12-02 S1 24
6 2021-12-02 S1 24
7 2021-12-02 S1 24
8 2021-12-02 S1 3
9 2021-12-02 S2 14
10 2021-12-02 S2 1