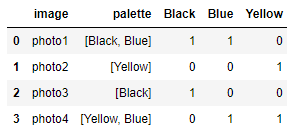
i got a .csv file of the following form:
I need to parse through the whole csv file and replace 0 with 1 on the corresponding color, when I find it on the "Palette" section.
For example, for the first row, there are 2 values on the "Palette" section of the image, "Black" and "Blue". I need to replace the corresponding colors in the same row with 1 (so Black and Blue sections).
Any help would be appreciated.
Thank you
CodePudding user response:
I have something, but I'm not sure how it'll scale.
Test dataframe:
df = pd.DataFrame({
"image" : ['photo1', 'photo2', 'photo3', 'photo4'],
"palette" : ['["Black", "Blue"]', 'Yellow', 'Black', '["Yellow", "Blue"]']
})
Output:
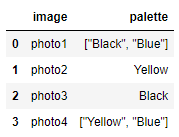
First step: convert the strings to actual lists.
def wrap_eval(x):
try:
return eval(x)
except:
return [x]
df["palette"] = df["palette"].apply(wrap_eval)
Output; it looks very similar, but if you check for example, df.loc[0, "palatte"], you'll see that we have a list of strings now rather than a string that happens to look like a list:
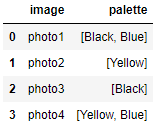
Now, we're going to iterate down the rows, (1) test to see if a column exists for each colour in the "palette" list in each row, (2) if it doesn't, add the column, with values of zero all the way down, and lastly (3), the column will exist by now, so set the value for it in this row to 1.
for i, row in df.iterrows():
for colour in row["palette"]:
try:
df[colour] # (1) in the steps above.
except:
df[colour] = 0 # (2)
finally:
df.loc[i, colour] = 1 # (3)