As the title says I'm looking for some tips on how to compress PDF and EPUB documents. I have a large dataset of documents (pdf and epub) and static graphics (png, jpeg, webp) that I'm trying to compress (preferably losslessly). As for the images I have a script that losslessly reduces the size by about 15% on average and was thinking of using the same tool to reduce the size of documents because the majority of their size is due to images. My approach for epub is somewhat straightforward as they are basically zip files: I extracted the content, re-encoded the images and zipped the rest with the highest compression setting. The trouble comes with the pdfs because I've never worked with them and they are not as simple as epubs. So my question is: is there any way to simply extract the images from pdfs and put them back after processing them without messing up some internal structure? Or maybe my approach is too cumbersome and there are better tools for doing the job of compression for pdfs (and even epubs). Any tips are greatly appreciated, Thanks!
CodePudding user response:
You can try the HexaPDF command line tool with the 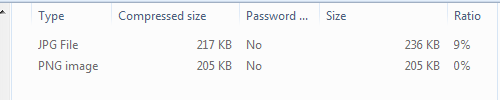
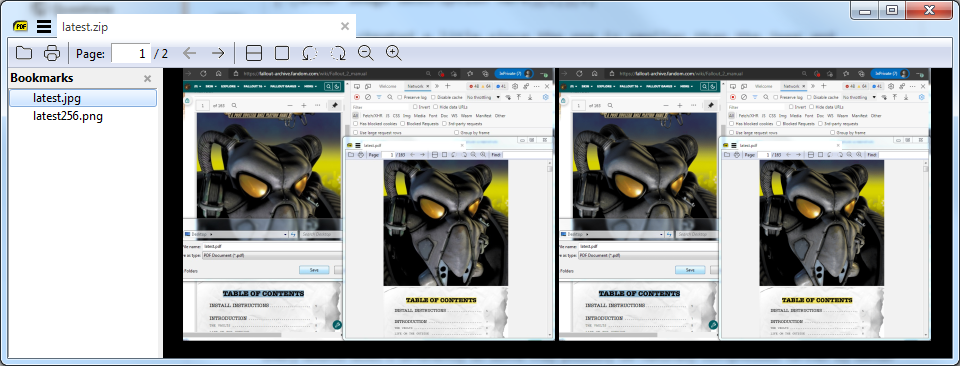
I admit I cheated a little since I made the the png colour range smaller than the jpeg and normally with alpha you may see otherwise but for a PDF png is better when gamut is reduced so what about in a PDF? Well naturally the PDF will be bigger than the zip, because of all the overheads that come with a PDF the zip is 422 KB the PDF is 531 KB thus bigger.
You could try IlovePDF compression at different settings to see how much degradation you can accept but remember the penalty for over compression is jpeg 8x8 pixel blocks with artifacts such as "haloed text" if scanned and a serious increase in decompression timing from page to page or first opening time if coloured photos.
So using medium (good) online compression what happens to the lossless png well the file size drops drastically, but also the quality as its no longer lossless.
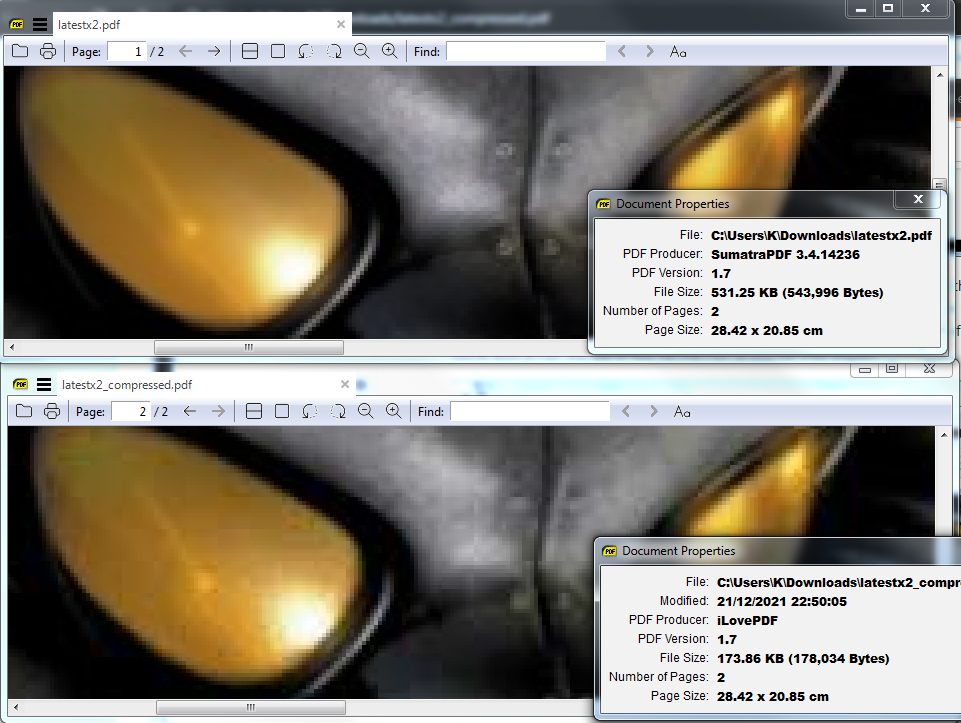
The best option for image based text pages is to drop the colour gamut on most pages to 4 bit grey-scale PNG, depending on the content, but that's not easy to do on a generic file basis if colour is involved on some pages.
For your querry about structure, since a PDF is a random collection of decimal indexed objects, naturally they will need to be rebuilt totally differently to the source, since in-place replacement is often problematic except done by a dedicated PDF library command.
As you say ePub is very easy, unzip > convert images enblock via script and rezip and all of that could be done in the windows command line using tar, vbs and mspaint.