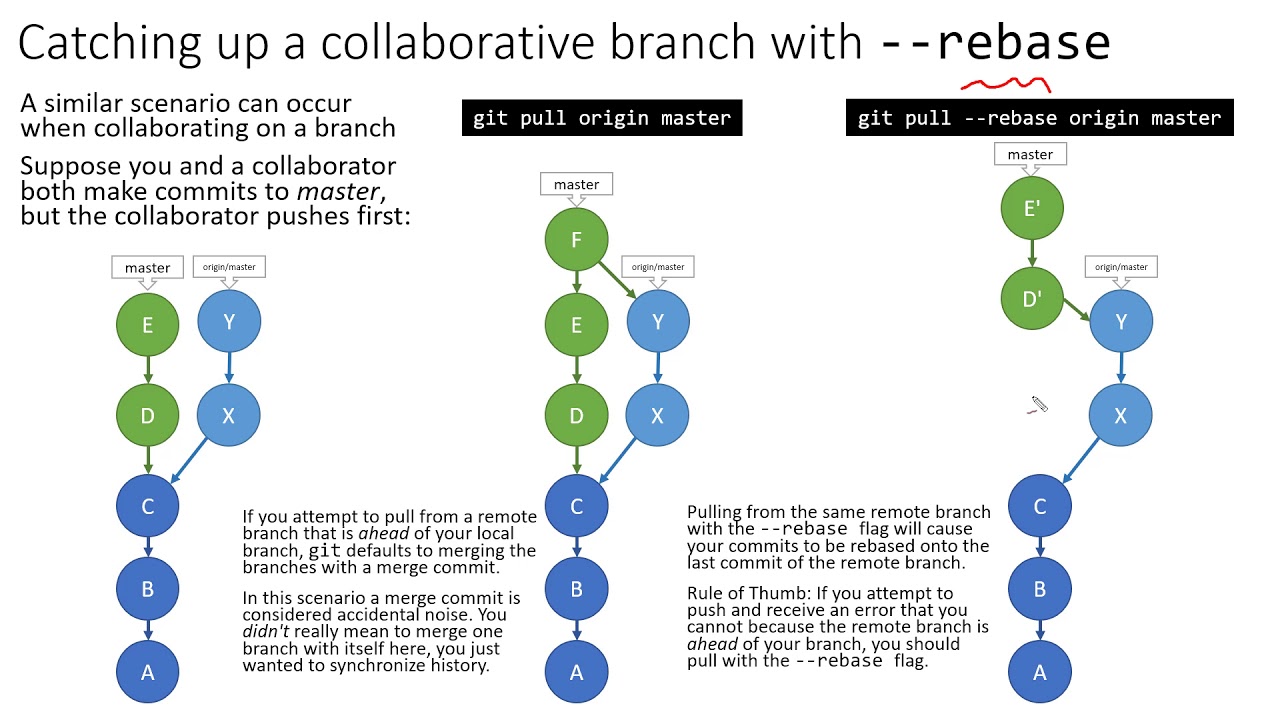
The above diagram gives us a good idea of git pull and git pull --rebase. I'm getting confused about one thing here. Let me elaborate -
1. Case 1 -> git pull --rebase origin master
My local master branch after the command - A B C X Y D' E'
My remote master branch after the command - A B C X Y
If I now execute, git push origin master:master, my remote master branch will look like - A B C X Y D' E'
2. Case 2 -> git pull origin master
My local master branch after the command - A B C D E F
My remote master branch after the command - A B C X Y
How will git push origin master:master behave in this case? I'm not able to understand why in any scenario we would want to use git pull without --rebase?
CodePudding user response:
What you're missing is, I think, best explained by avoiding git pull. Still, let's imagine git pull had a hypothetical --merge option so that we could say you are running git pull --merge origin master. (You are getting a merge already; this option would be the default, if it were an explicit option.) That is, your git pull origin master runs the equivalent of:
git fetch origin; thengit merge -m "merge branch master of <url>" origin/master.
That produces the graph, which they drew as:
A--B--C--D--E--F <-- master
\ /
X----Y
(I've turned it sideways here. Rotate 90˚ ccw to match.)
I'd now like to suggest redrawing it like this:
D--E
/ \
A--B--C F <-- master
\ /
X--Y
Now that I've drawn the graph this way, which commits are "on" branch master? If you pick A-B-C-D-E-F, why didn't you also pick X-Y? If you pick A-B-C-X-Y-F, why didn't you also pick D-E?
The fact is that all eight commits, including both D-E and X-Y, are "on" branch master. The name master identifies commit F, but commit F is a merge commit. It reaches back to two different commits: E and Y. Those two different commits reach back to D and X respectively, and those two different commits reach back to a single common shared starting point C.
Commit C was the merge base of the two tip commits, at the time you had Git run git merge, via git pull. So Git found out what you did, on the C-to-E leg, by running a diff between the snapshots in commits C and E. Then Git found what they did, on the C-to-Y leg, by running a diff between C and Y. Then Git took the two diffs and combined them, applied the combined result to the shared snapshot from commit C, and used that to make new merge commit F.
Merge commit F has one snapshot, just like every other commit. Where it's different from the other commits is that it has two parents, E and Y. So you can ask Git: *what changed from E to F and what you'll get is the changes brought in because of the lower (in my drawing) leg of the merge; or you can ask what changed from Y to F and you'll see what changes were brought in because of the upper leg of the merge.
In any case, this is the job (and point) of a merge: to combine work, keeping a record of the fact that the work was combined. You can now see exactly what happened: you did something while they were working, they did something while you were working, and then you combined it all at once.
Using rebase makes for a "cleaner" history: it looks like they did something, you waited for them to finish, then you started on your task knowing what they'd done and did your work and committed it. That's not really what happened, but maybe it's just as good. Maybe it's better because to a future you, or them, or whoever, it's simpler: it does not require figuring out whether something went wrong during the work-combining. But if something did go wrong, it may hide what that something was, making things worse for the future you/them/whoever.
This is why you have a choice: one may be better than the other, or not.