This is a bit of weird question, but I have been importing property data from an api in the format of a json file within python. I then use Pandas to convert the json into a dataframe.
I am having trouble manipulating the data within the data frame. My current data is set up as to be formatted like this table.
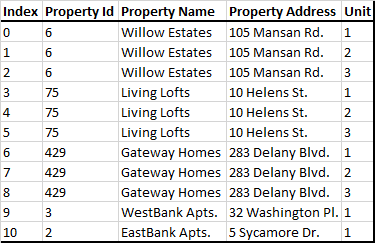
Each Property is assigned a name and a property id and address, and there is a record for every unit within a property. Ideally, I would like to create multiple data frames separated by property id, such that it would look like this.
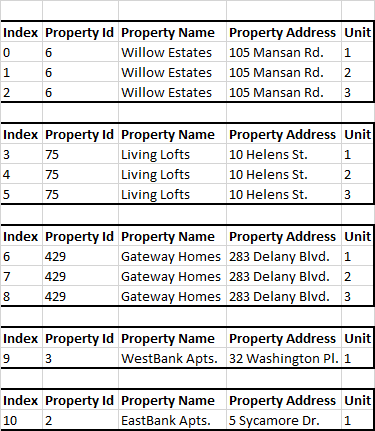
My only problem here is that due to their being some organization issues, there are about 100 different property ids, and none of the ids are in order. They all have a random number from 1 - 1000.
Is there a way to automatically separate dataframes based on property id by using some sort of unique identifier combined with a for loop ?
I don't really know how to approach the scenario. Thanks!
CodePudding user response:
Try this:
list_of_dataframes = [x for _, x in df.groupby(df['Property Id'].ne(df['Property Id'].shift(1)).cumsum())]
Now list_of_dataframes is a list of dataframes, where each dataframe contains the rows where the Property Id was consecutively the same. So Property Ids 1 1 1 9 9 9 1 1 1 would return 3 dataframes, one containing the first three 1's, the second containing the next three 9's, and the last containing the last three 1's.
If don't want the groups to be based on the consective order (i.e., you want 1 1 1 9 9 9 1 1 1 to be two dataframes, the first containing all six 1's, and the second containing the three 9's), you can do this:
list_of_dataframes = [x for _, x in df.groupby(df['Property Id'])]