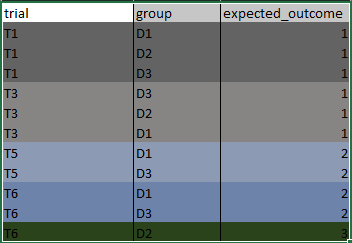
I would like to identify unique sets of row values in a column based on row values in another column to ultimately create a new column in a dataframe. The following picture illustrates my problem and the expected result (expected_outcome column).
For example:
The first 3 rows have values
T1in the columntrial, and valuesD1, D2, D3in the columngroup.The next 3 rows have values
T3in the columntrial, and valuesD3, D2, D1in the columngroup.
Because the set D1, D2, D3 has the same contain as D3, D2, D1, I want all the 6 rows to have the same value in column expected_outcome.
My data is way more complex than that. I may have to make this grouping over more than 2 columns. So, I prefer a generic solution to this problem. Below is the data in the picture.
test_data <- data.frame(
trial = c("T1", "T1", "T1", "T3", "T3", "T3", "T5", "T5", "T6", "T6", "T6"),
group = c("D1", "D2", "D3", "D3", "D2", "D1", "D1", "D3", "D1", "D3", "D2")
)
CodePudding user response:
You could do something like this via tidyverse.
library(tidyverse)
test_data %>%
group_by(trial) %>%
summarize(type = paste(sort(unique(group)), collapse = ", "), group) %>%
group_by(type) %>%
mutate(expected_outcome = cur_group_id()) %>%
ungroup() %>%
dplyr::select(-"type")
Output
# A tibble: 11 × 3
trial group expected_outcome
<chr> <chr> <int>
1 T1 D1 1
2 T1 D2 1
3 T1 D3 1
4 T3 D3 1
5 T3 D2 1
6 T3 D1 1
7 T5 D1 2
8 T5 D3 2
9 T6 D1 1
10 T6 D3 1
11 T6 D2 1
CodePudding user response:
test_data %>%
arrange(across(everything())) %>%
group_by(trial) %>%
mutate(expected_outcome = toString(group)) %>%
group_by(expected_outcome) %>%
mutate(expected_outcome = cur_group_id())
trial group expected_outcome
<chr> <chr> <int>
1 T1 D1 1
2 T1 D2 1
3 T1 D3 1
4 T3 D1 1
5 T3 D2 1
6 T3 D3 1
7 T5 D1 2
8 T5 D3 2
9 T6 D1 1
10 T6 D2 1
11 T6 D3 1