Im having a problem with scraping the table of this website, I should be getting the heading but instead am getting
AttributeError: 'NoneType' object has no attribute 'tbody'
Im a bit new to web-scraping so if you could help me out that would be great
import requests
from bs4 import BeautifulSoup
URL = "https://www.collincad.org/propertysearch?situs_street=Willowgate&situs_street_suffix" \
"=&isd[]=any&city[]=any&prop_type[]=R&prop_type[]=P&prop_type[]=MH&active[]=1&year=2021&sort=G&page_number=1"
s = requests.Session()
page = s.get(URL)
soup = BeautifulSoup(page.content, "lxml")
table = soup.find("table", id="propertysearchresults")
table_data = table.tbody.find_all("tr")
headings = []
for td in table_data[0].find_all("td"):
headings.append(td.b.text.replace('\n', ' ').strip())
print(headings)
CodePudding user response:
What happens?
Note: Always look at your soup first - therein lies the truth. The content can always be slightly to extremely different from the view in the dev tools.
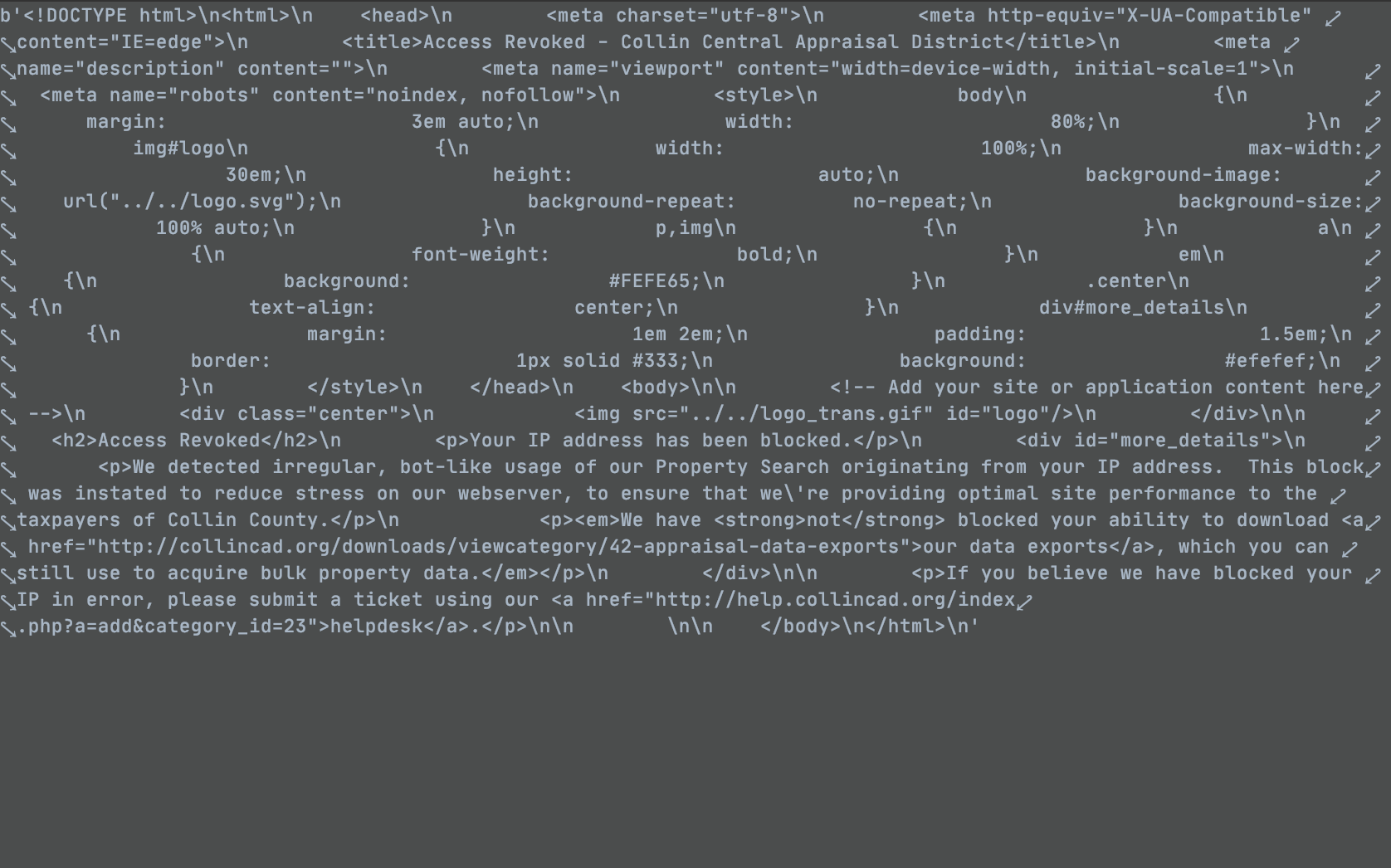
Access Revoked
Your IP address has been blocked.
We detected irregular, bot-like usage of our Property Search originating from your IP address. This block was instated to reduce stress on our webserver, to ensure that we're providing optimal site performance to the taxpayers of Collin County.
We have not blocked your ability to download
You should add some headers to your request because the website is blocking your request. In your specific case, it will be enough to add a
User-Agent:import requests from bs4 import BeautifulSoup headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36' } URL = "https://www.collincad.org/propertysearch?situs_street=Willowgate&situs_street_suffix" \ "=&isd[]=any&city[]=any&prop_type[]=R&prop_type[]=P&prop_type[]=MH&active[]=1&year=2021&sort=G&page_number=1" s = requests.Session() page = s.get(URL, headers=headers) soup = BeautifulSoup(page.content, "lxml") table = soup.find("table", id="propertysearchresults") table_data = table.tbody.find_all("tr") headings = [] for td in table_data[0].find_all("td"): headings.append(td.b.text.replace('\n', ' ').strip()) print(headings)If you add headers, you will still have error, but in the row:
headings.append(td.b.text.replace('\n', ' ').strip())You should change it to
headings.append(td.text.replace('\n', ' ').strip())because
tddoesn't always haveb.