Consider the following HTML:
<html>
<body>
<h3>Title 1</h3>
<p>Text A</p>
<p>Text B</p>
<h3>Title 2</h3>
<p>Text C</p>
<h3>Title 3</h3>
<p>Text D</p>
</body>
</html>
If I read this file in R, using xml2 library:
a = read_xml('test.html',as_html=T)
h3 = xml_find_all(a,'//h3')
xml_text(h3[[2]]) # outputs 'Title 2'
p = xml_find_all(a,'//p')
xml_text(p[[3]]) # outputs 'Text C'
How do I know which paragraph (p) comes right after each title (h3), considering that in my real file there may be multiple paragraphs after each title, and there are hundreds of titles, and thousands of paragraphs?
EDIT
If I convert a to a list, I can see in RStudio where are the titles and paragraphs:
a = as_list(a)
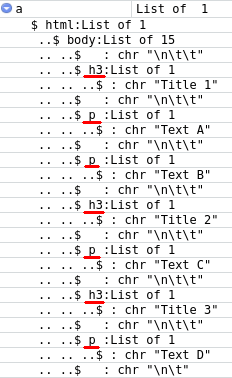
But I just can't find a way to get which list item is a h3 and which is a p!
CodePudding user response:
You could do this with rvest as well. Use an adjacent sibling combinator to first get a list of p tags that immediately follow an h3, then use an xpath to get the preceding h3. Wrap that in data.frame() and an outer map_dfr() to get a single DataFrame result which maps title to the immediate following paragraph.
library(rvest)
library(magrittr)
library(purrr)
html <- '<html>
<body>
<h3>Title 1</h3>
<p>Text A</p>
<p>Text B</p>
<h3>Title 2</h3>
<p>Text C</p>
<h3>Title 3</h3>
<p>Text D</p>
</body>
</html>'
page <- read_html(html)
df <- page %>%
html_elements("h3 p") %>%
map_dfr(., ~ data.frame(
title = .x %>% html_element(xpath = ".//preceding-sibling::h3[1]") %>% html_text(),
para = .x %>% html_text()
))
print(df)
Same logic with xml2
library(magrittr)
library(purrr)
library(xml2)
html <- '<html>
<body>
<h3>Title 1</h3>
<p>Text A</p>
<p>Text B</p>
<h3>Title 2</h3>
<p>Text C</p>
<h3>Title 3</h3>
<p>Text D</p>
</body>
</html>'
page <- read_xml(html)
df <- page %>%
xml_find_all(".//h3/following-sibling::p[1]") %>%
map_dfr(., ~ data.frame(
title = .x %>% xml_find_first(".//preceding-sibling::h3[1]") %>% xml_text(trim = T),
para = .x %>% xml_text(trim = T)
))
print(df)
CodePudding user response:
I just discovered that I can convert the XML to a list, and then get the names of the body subobject in the list:
a = read_html('<html>
<body>
<h3>Title 1</h3>
<p>Text A</p>
<p>Text B</p>
<h3>Title 2</h3>
<p>Text C</p>
<h3>Title 3</h3>
<p>Text D</p>
</body>
</html>')
a = as_list(a)
names(a$html$body)
[1] "" "h3" "" "p" "" "p" "" "h3" "" "p" "" "h3" "" "p" ""
Now I know the positions of each h3 and p, and can iterate successfully through them.