I have source dataframe, df like below.
| order_id | prod_id | date | authorized |
|---|---|---|---|
| 111 | P | 2022-01-01 00:00:00 | N |
| 111 | P | 2022-01-02 00:00:00 | N |
| 111 | P | 2022-01-03 00:00:00 | Y |
| 111 | Q | 2022-01-02 00:00:00 | Y |
| 112 | P | 2022-01-01 00:00:00 | N |
| 112 | P | 2022-01-02 00:00:00 | Y |
| 112 | Q | 2022-01-01 00:00:00 | N |
| 112 | Q | 2022-01-02 00:00:00 | N |
| 112 | Q | 2022-01-03 00:00:00 | N |
| 112 | Q | 2022-01-04 00:00:00 | N |
| 113 | P | 2022-01-01 00:00:00 | N |
| 113 | P | 2022-01-02 00:00:00 | Y |
| 113 | P | 2022-01-03 00:00:00 | Y |
| 113 | P | 2022-01-04 00:00:00 | Y |
| 113 | P | 2022-01-05 00:00:00 | Y |
| 114 | Z | 2022-01-05 00:00:00 | Y |
my goal is to create a target dataframe like below
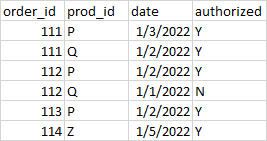
Here is the logic to be implemented for target dataframe creation:
a) for an order_id and prod_id combination take the first row(sorted by date ascending) where authorized=Y
b) for an order id and prod id combination, if none of the records have authorized = 'Y', take the first row,sorted by date ascending.
Is there any way to implement this efficiently, in Pandas?. I did some googling, but couldn't find a solution. Thanks in advance.
CodePudding user response:
Sort your dataframe by authorized and date columns then group by order_id and product_id columns. Finally, get the first row of each group.
# Convert date as datetime64
df['date'] = pd.to_datetime(df['date'], dayfirst=False)
out = df.sort_values(['authorized', 'date'], ascending=[False, True]) \
.groupby(['order_id', 'prod_id']).first().reset_index()
print(out)
# Output
order_id prod_id date authorized
0 111 P 2022-01-03 Y
1 111 Q 2022-01-02 Y
2 112 P 2022-01-02 Y
3 112 Q 2022-01-01 N
4 113 P 2022-01-02 Y
5 114 Z 2022-01-05 Y