I have the next DataFrame:
x = [{'name': 'a.1,b,c,d,e,a,f,g,h'}, {'name': 'b.1,c,a.1,d,e.1,g,a,h'}, {'name': 'b.1,d,e,a,f.1,c,r'}]
df = pd.DataFrame(x)
I need to filter column -> 'name' and delete the values a and a.1, and to get the next result:
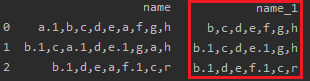
I will be grateful for help
CodePudding user response:
You can use list comprehension:
df['name_1'] = [','.join([a for a in d.split(',') if a not in set(('a','a.1'))]) for d in df['name']]
You can also apply the very same function to the 'name' column:
df['name_1'] = df['name'].apply(lambda row : ','.join([a for a in row.split(',') if a not in set(('a','a.1'))]))
Output:
name name_1
0 a.1,b,c,d,e,a,f,g,h b,c,d,e,f,g,h
1 b.1,c,a.1,d,e.1,g,a,h b.1,c,d,e.1,g,h
2 b.1,d,e,a,f.1,c,r b.1,d,e,f.1,c,r
CodePudding user response:
You can use Dataframe's apply function this:
def update(r):
items = r.split(',')
return ','.join(filter(lambda x: x != 'a.1' and x != 'a', items))
df['name_1'] = df['name'].apply(update)
df
Output:
name name_1
0 a.1,b,c,d,e,a,f,g,h b,c,d,e,f,g,h
1 b.1,c,a.1,d,e.1,g,a,h b.1,c,d,e.1,g,h
2 b.1,d,e,a,f.1,c,r b.1,d,e,f.1,c,r
CodePudding user response:
You can just use replace:
df['name'] = df['name'].replace({'a.1,':'','a':''},regex=True).str.replace(',,',',')
name
0 b,c,d,e,f,g,h
1 b.1,c,d,e.1,g,h
2 b.1,d,e,f.1,c,r
CodePudding user response:
Another regex option:
df['name'].str.replace(r"a\.1|a","").str.replace(r'(?<=,),|^,',"")
0 b,c,d,e,f,g,h
1 b.1,c,d,e.1,g,h
2 b.1,d,e,f.1,c,r
CodePudding user response:
Try this:
df['name_1'] = df['name'].str.split(',').apply(lambda cell_value: ",".join(filter(lambda x: x not in {'a', 'a.1'}, cell_value)))
CodePudding user response:
I am surprised that all proposed regex answers use two passes to achieve the goal.
Here is a regex answer that relies on a single expression:
# list of substrings to remove
# IMPORTANT: if an element is a left-aligned substring of another
# the substring should be ordered after the longer string
# here "a" is after "a.1"
remove = ['a.1', 'a']
import re
regex = '({0}),|,({0})'.format('|'.join(map(re.escape, remove)))
df['name_1'] = df['name'].str.replace(regex, '', regex=True)
Alternative if group capturing is unwanted:
regex = '(?:{0}),|,(?:{0})'.format('|'.join(map(re.escape, remove)))
Example:
name name_1
0 a.1,b,c,d,e,a,f,g,h b,c,d,e,f,g,h
1 b.1,c,a.1,d,e.1,g,a,h,a b.1,c,d,e.1,g,h
2 b.1,d,e,a,f.1,c,r b.1,d,e,f.1,c,r
Format of the generated regex:
'(a\\.1|a),|,(a\\.1|a)'
# or for the alternative
'(?:a\\.1|a),|,(?:a\\.1|a)'
CodePudding user response:
This might help:
df['name1'] = [x.replace("a.1", "") for x in df.name]
df['name1'] = [x.replace("a", "") for x in df.name1]