I have created the following dataframe:
d = {'x': [0,0,1,1,1,1,1,2,2,2], 'y': [67,-5,78,47,88,12,-4,14,232,28]}
df = pd.DataFrame(data=d)
print(df)
which looks like this:
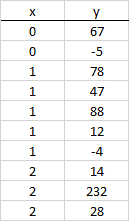
I want to calculate a column "z" which is the cumulative of column "y" by column "x". So, I calculate the cumulative distribution as long as x is of the same value. The resulting dataframe should look like this:
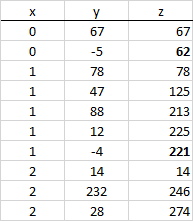
So, when the column X changes value a new cumulative distribution is calculated.
How can I do that in python?
CodePudding user response:
You can perform the cumsum per group using groupby cumsum:
df['z'] = df.groupby('x')['y'].cumsum()
output:
x y z
0 0 67 67
1 0 -5 62
2 1 78 78
3 1 47 125
4 1 88 213
5 1 12 225
6 1 -4 221
7 2 14 14
8 2 232 246
9 2 28 274
CodePudding user response:
cumsum is what you are searching for :
df['z'] = df.groupby('x')['y'].cumsum()