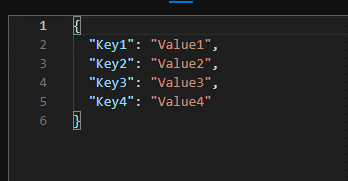
I have a problem with converting JSON to CSV. JSON looks like that:
{
"Key1": "Value1",
"Key2": "Value3",
"Key3": "Value2",
...
}
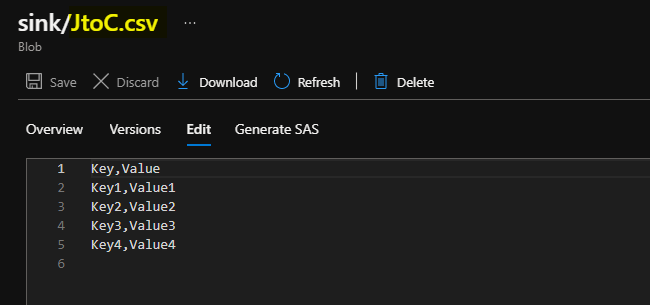
And I expect the CSV in this format:
Key, Value
Key1, Value1
Key2, Value2
Key3, Value3
...
As you see keys and values are stored in column. Is it possible to do that in data flow in Azure Data Factory?
CodePudding user response:
You can make use of flatten transformation in data flow. Please check the below Microsoft documentation page.
Data flow:
- Add
Sourceand connect it to the JSON Input file. In source options under JSON settings, select the document form as Single document.
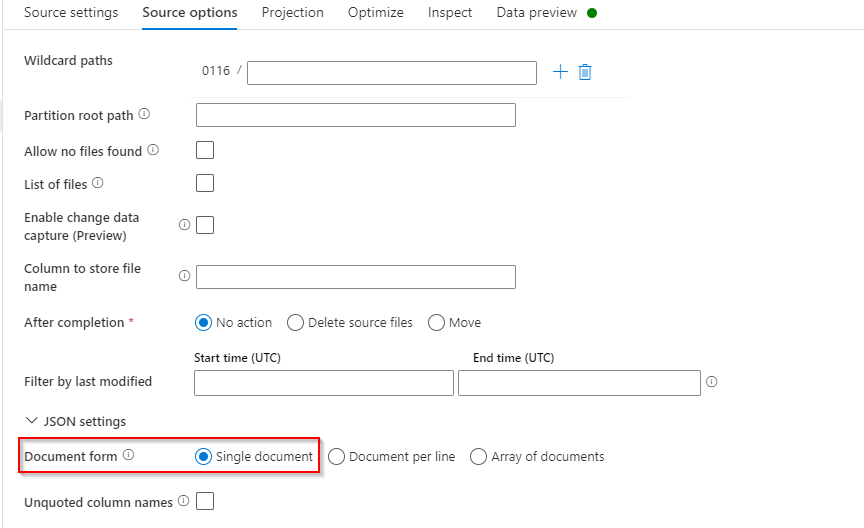
Source Data preview:

- Add
derived columnafter source to add a dummy column with a constant value to later use it in Unpivot transformation.
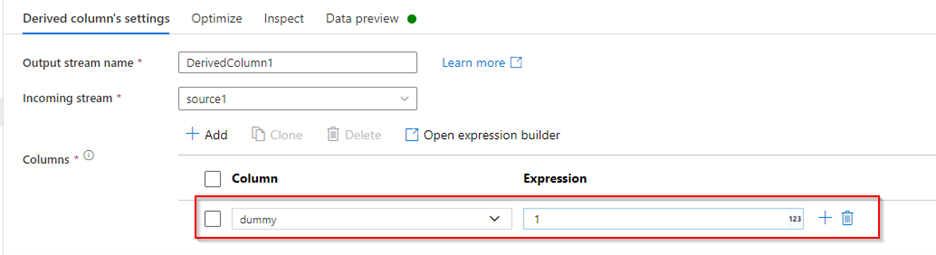
Derived column Data preview:

Add
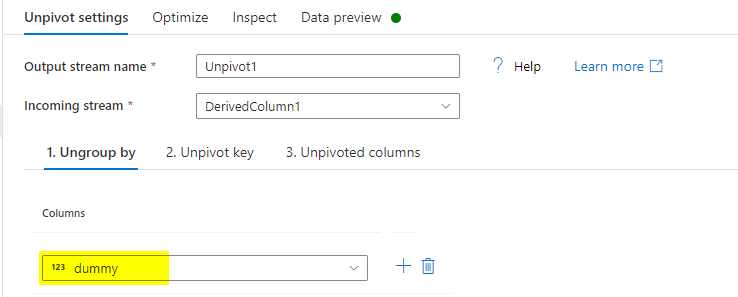
Unpivottransformation after Derived column, to convert columns to rows. Under Unpivot settingsa) Ungroup by: Select dummy column.
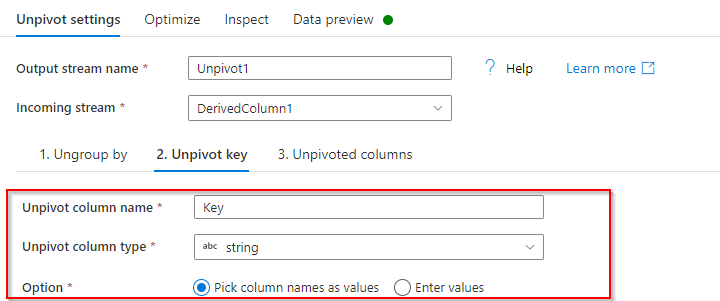
b) Unpivot key: Give a name to an unpivot column (Ex: Key), type as ‘string’.
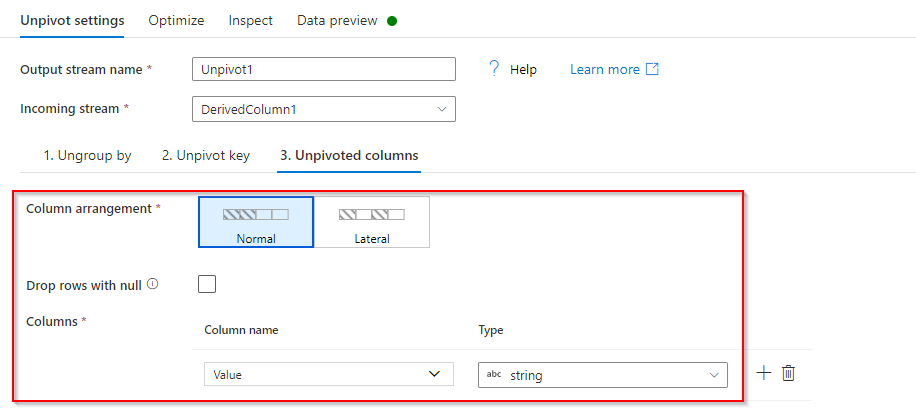
c) Unpivoted columns: Give a column name for the data in unpivoted columns.
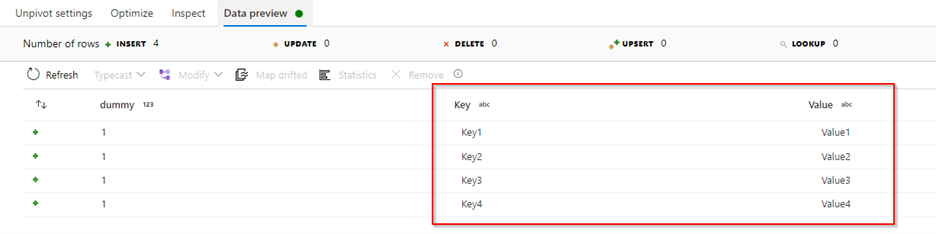
Unpivot Data preview:
- Add
Selecttransformation after Unpivot to remove the dummy column and select only required columns to the output.
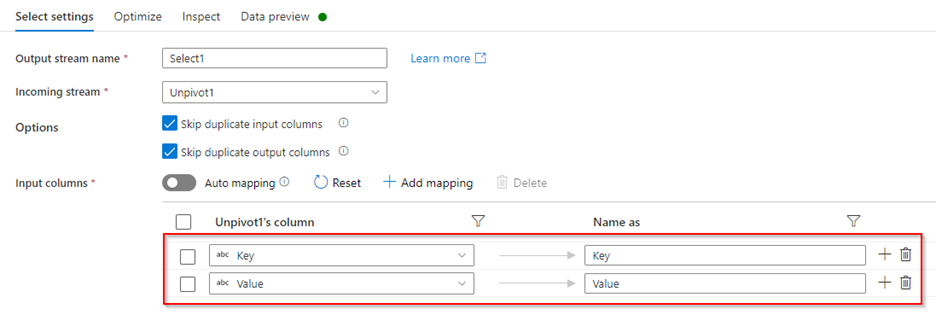
Select Data preview:
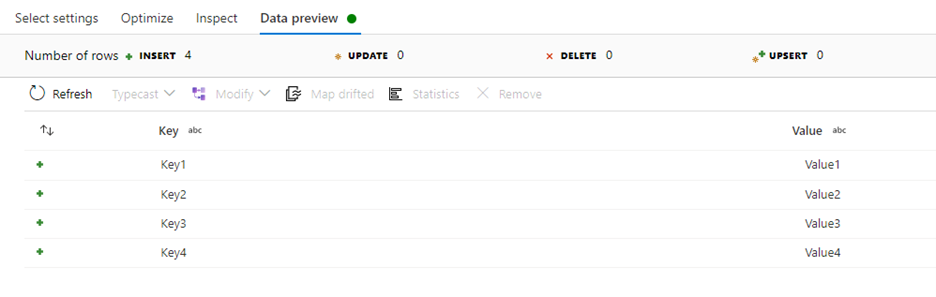
- Add
sinktransformation at the end and connect to sink delimited dataset. In Settings, if you select the File name option as Output to single file, you can provide the sink file name.
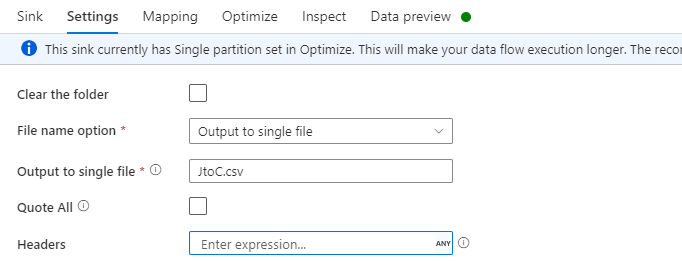
Sink Data preview:
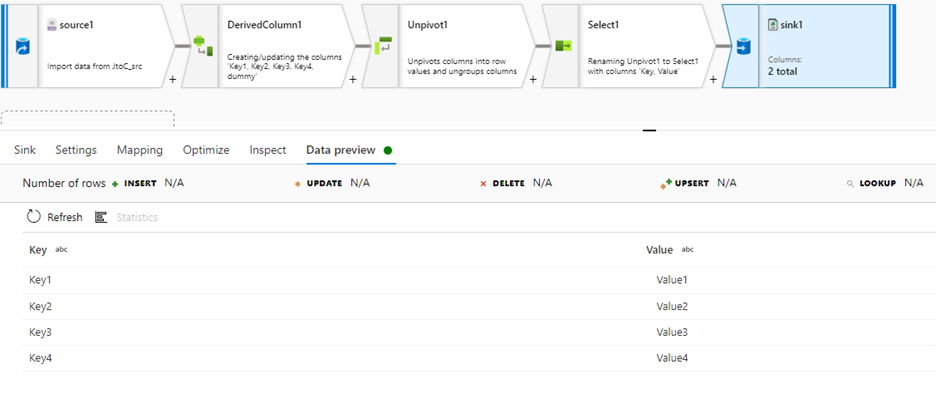
Output: