Is it possible to have a custom function to truncate the contents of a defined DIV on a blog post page to use as the summary on the blog index page. So rather than using $the_content or $the_excerpt - Is it possible to create $the_customContent and have some PHP which checks the blog post page and collects the content of the div with class "ThisIsTheContentToUse" - reason for this is that my blog posts have content on the page above the content I want to be included as the blog summary on the blog index page - so either want to tell WP to ignore those blocks of content, or, probably easier - just tell WP where the content to truncate is - e.g. in the "ThisIsTheContentToUse" div... possible?
If so... how? Can't seem to find anything online that defines this custom functionality - surely I can't be the first person to want to do this...?
Would apply_filters make this possible?
https://developer.wordpress.org/reference/hooks/the_content/
So, The blog post is structured as:
<div >
<h2>The title is here</h2>
<ul>
</div>
<div >
<li>Bullet 1</li>
<li>Bullet 2</li>
<li>Bullet 3</li>
</ul>
</div>
<div >
<p>The content starts here</p>
</div>
So, currently with the basic get_the_content, the result is:
"The title is here Bullet 1 Bullet 2 Bullet 3 The content starts here"
But what I want is just the content of the "ThisIsTheContentToUse" div.
So it would be:
"The content starts here"
CodePudding user response:
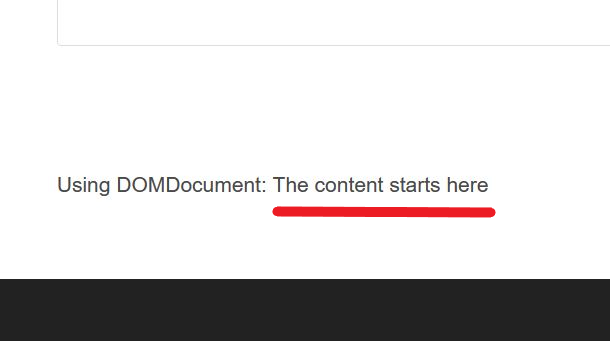
There are several ways we could set this up, two of which are popular. We could use the php DOMDocument class as well as the good old favorite of mine regular expressions!
Using DOMDocument:
- First, we get the content using
get_the_contentfunction. - Then, we'll read the content using
DOMDocument. - And finally parse it.
$test = get_the_content();
if (class_exists('DOMDocument'))
{
$dom = new DOMDocument();
$class_name = 'ThisIsTheContentToUse';// This is the class name of your div element
@$dom->loadHTML($test);
$nodes = $dom->getElementsByTagName('div');
foreach ($nodes as $element)
{
$element_class = $element->getAttribute('class');
if (substr_count($element_class, $class_name))
{
echo 'Using DOMDocument: ' . $element->nodeValue;
}
}
}
Which will output this:
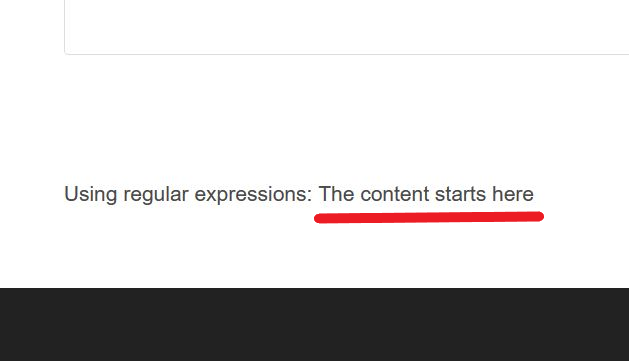
Using Regular Expressions:
- We use
preg_matchfunction. - This is the pattern
<div >([^w]*?)<\/div>.
$test = get_the_content();
preg_match('/<div >([^w]*?)<\/div>/', $test, $match);
$new_excerpt = $match[1];
echo 'Using regular expressions: ' . $new_excerpt;
Which will output this: