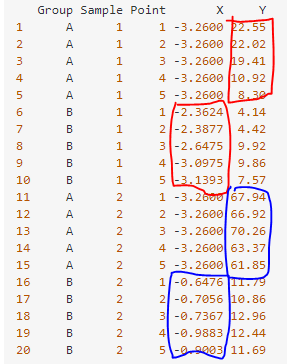
Here's what my data looks like. Long story short, I want to scatterplot Y values from Group A vs respective X values from Group B and optionally color it by Sample.
I do a lot of plotting of data like this (with many more variables), but it's always within a subset like subset(data, Group=='A') or subset(data, Group=='B'). This is the rare case when I need to plot across groups.
The plot code itself is simple:
ggplot(data, aes(x=X(B), y=Y(A), color=as.factor(Sample)))
geom_point()
I realize that my X(B) and Y(A) won't work; that's just to illustrate the objective. I also assume there's a way to spit out a new dataset containing only the X(B) and Y(A) values; certainly open to any approach, but I prefer to work in GGPLOT for the actual graphs. Here's my dataset for reproducibility:
data <- structure(list(Group = c("A", "A", "A", "A", "A", "B", "B", "B",
"B", "B", "A", "A", "A", "A", "A", "B", "B", "B", "B", "B"),
Sample = c(1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 2L, 2L,
2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L), Point = c(1L, 2L, 3L, 4L,
5L, 1L, 2L, 3L, 4L, 5L, 1L, 2L, 3L, 4L, 5L, 1L, 2L, 3L, 4L,
5L), X = c(-3.26, -3.26, -3.26, -3.26, -3.26, -2.3624, -2.3877,
-2.6475, -3.0975, -3.1393, -3.26, -3.26, -3.26, -3.26, -3.26,
-0.6476, -0.7056, -0.7367, -0.9883, -0.9003), Y = c(22.55,
22.02, 19.41, 10.92, 8.3, 4.14, 4.42, 9.92, 9.86, 7.57, 67.94,
66.92, 70.26, 63.37, 61.85, 11.79, 10.86, 12.96, 12.44, 11.69
)), class = "data.frame", row.names = c(NA, -20L))
CodePudding user response:
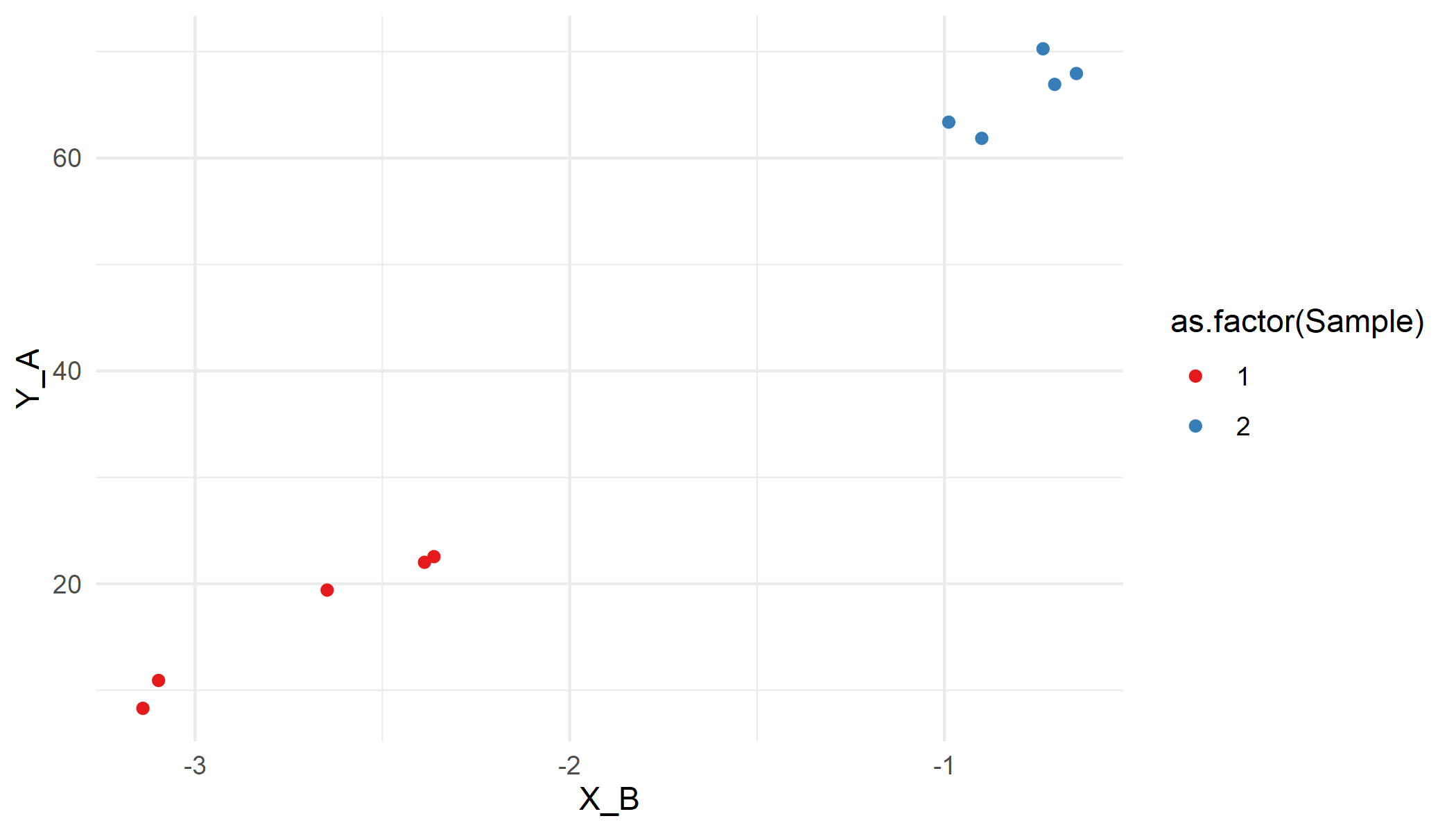
You can get the equivalent of X(B) and Y(A) by pivoting:
library(tidyverse)
pivoted <- data %>%
pivot_wider(names_from = Group, values_from = X:Y)
# data before pivoting
head(as_tibble(data))
# # A tibble: 6 x 5
# Group Sample Point X Y
# <chr> <int> <int> <dbl> <dbl>
# 1 A 1 1 -3.26 22.6
# 2 A 1 2 -3.26 22.0
# 3 A 1 3 -3.26 19.4
# 4 A 1 4 -3.26 10.9
# 5 A 1 5 -3.26 8.3
# 6 B 1 1 -2.36 4.14
# after pivoting
head(pivoted)
# # A tibble: 6 x 6
# Sample Point X_A X_B Y_A Y_B
# <int> <int> <dbl> <dbl> <dbl> <dbl>
# 1 1 1 -3.26 -2.36 22.6 4.14
# 2 1 2 -3.26 -2.39 22.0 4.42
# 3 1 3 -3.26 -2.65 19.4 9.92
# 4 1 4 -3.26 -3.10 10.9 9.86
# 5 1 5 -3.26 -3.14 8.3 7.57
# 6 2 1 -3.26 -0.648 67.9 11.8
Then you can easily adapt your illustration code:
ggplot(pivoted, aes(x=X_B, y=Y_A, color=as.factor(Sample)))
geom_point()
CodePudding user response:
You can rearrange the data frame using filter, select and bind_cols.
library(dplyr)
library(ggplot2)
data %>%
filter(Group == "A") %>%
select(Sample, Y) %>%
bind_cols(data %>%
filter(Group == "B") %>%
select(X))
Result:
Sample Y X
1 1 22.55 -2.3624
2 1 22.02 -2.3877
3 1 19.41 -2.6475
4 1 10.92 -3.0975
5 1 8.30 -3.1393
6 2 67.94 -0.6476
7 2 66.92 -0.7056
8 2 70.26 -0.7367
9 2 63.37 -0.9883
10 2 61.85 -0.9003
Then pipe that to ggplot:
data %>%
filter(Group == "A") %>%
select(Sample, Y) %>%
bind_cols(data %>%
filter(Group == "B") %>%
select(X)) %>%
ggplot(aes(X, Y))
geom_point(aes(color = factor(Sample)))
Result:
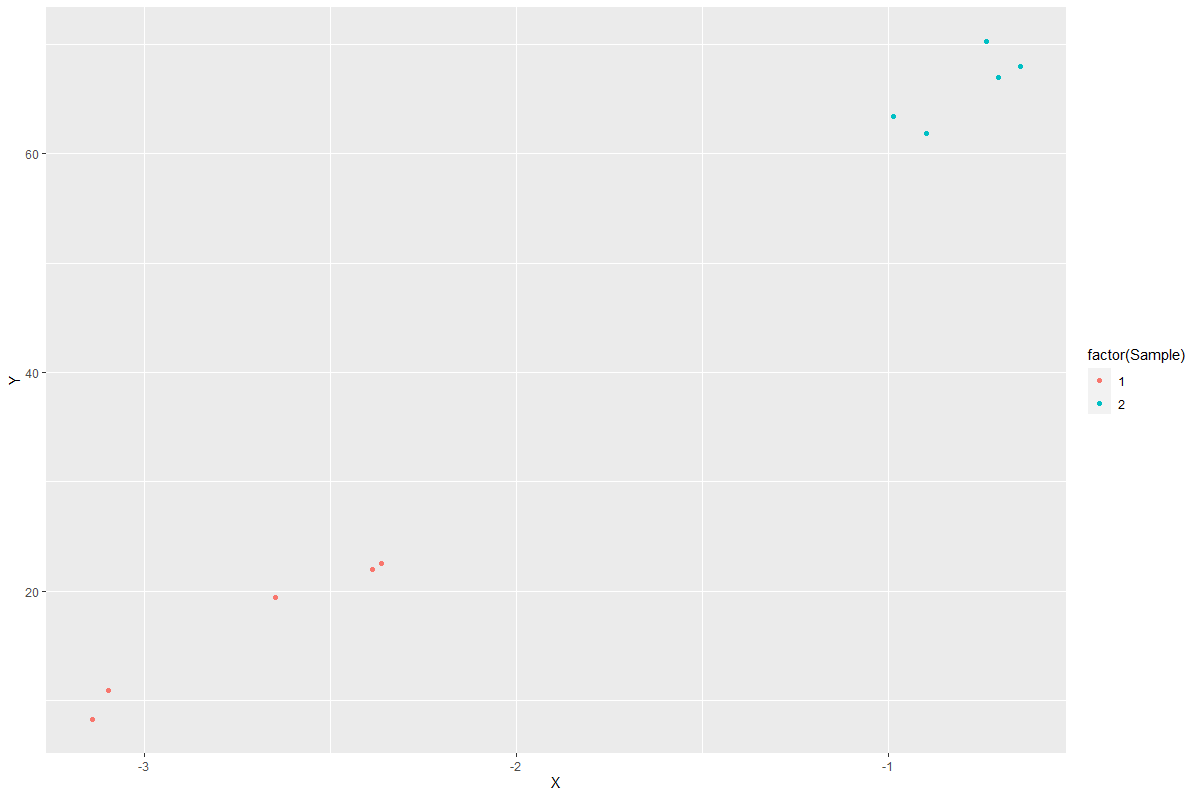
CodePudding user response:
Here's another way to reshape your data. We pivot longer to get the X and Y values on their own row, and then we can filter to keep just the Y values from A and the X values from B. Then we can reshape again to have just one row with an X and Y value for each Sample/Point compbination.
library(dplyr)
library(tidyr)
library(ggplot)
data %>%
pivot_longer(cols=c(X,Y)) %>%
filter((Group=="A" & name=="Y") | (Group=="B" & name=="X")) %>%
pivot_wider(id=c(Sample, Point), names_from = name, values_from = value) %>%
ggplot()
aes(X,Y, color=as.factor(Sample))
geom_point()
The main point is that you need to get your data in the right order before you try plotting it. ggplot always assumes you have "tidy" data. Try to avoid doing weird data manipulations when trying to plot.