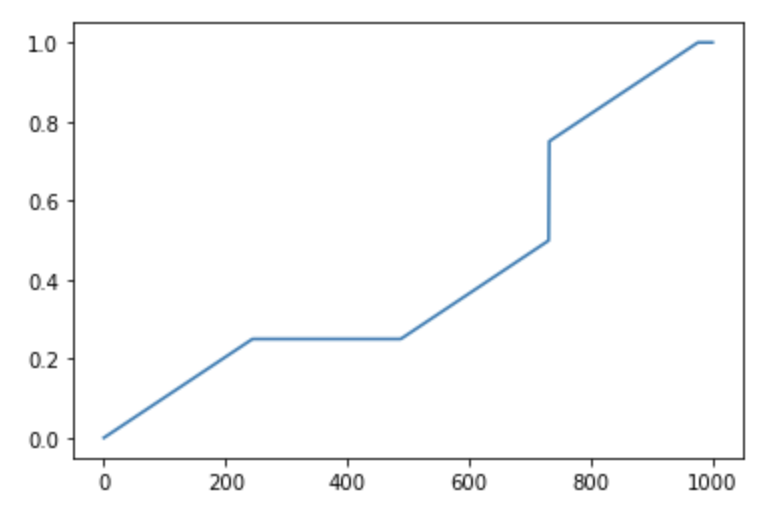
I wanted to take a quick look at the following distribution function and noticed that something is very wrong with the way I'm trying to do that. When applying the function to x_range, all values end up being 0. I am very confused about this and struggle to understand why that would be the case. Am I using numpy wrong in this situation? At least that is the only explanation I have, but I have not been able to find any sort of explanation for why I am seeing these results.
Below is my code.
from matplotlib import pyplot as plt
import numpy as np
def F(x):
return 0 if x <= 0 \
else .0025 * x if x <= 100 \
else .25 if x <= 200 \
else .0025 * x - .25 if x <= 300 \
else .0025 * x if x <= 400 \
else 1
x_range = np.linspace(0, 410, 1000)
plt.plot(np.vectorize(F)(x_range))
plt.show()
Also, is anyone aware of a more elegant way to simply plot a function over an interval? I am not really a fan of vectorizing the function and applying it to a specially generated array for the mere purpose of plotting. I assume there should be built-in matplotlib functionality to plot a function over some subspace of R.
CodePudding user response:
The documentation for 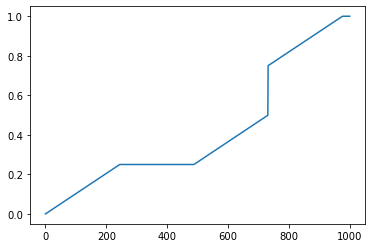
CodePudding user response:
maybe changing the numbers in "if statements" from int to float may help:
def F(x):
return 0.0 if x <= 0.0 \
else 0.0025 * x if x <= 100.0 \
else 0.25 if x <= 200.0 \
else 0.0025 * x - 0.25 if x <= 300.0 \
else 0.0025 * x if x <= 400.0 \
else 1.0
CodePudding user response:
Correcting F to consistently return a float:
In [45]: def F(x):
...: return .0 if x <= 0 \
...: else .0025 * x if x <= 100 \
...: else .25 if x <= 200 \
...: else .0025 * x - .25 if x <= 300 \
...: else .0025 * x if x <= 400 \
...: else 1.0
...:
And a smaller x:
In [46]: x = np.linspace(0,410,11)
In [47]: x
Out[47]: array([ 0., 41., 82., 123., 164., 205., 246., 287., 328., 369., 410.])
vectorize with otypes:
In [48]: np.vectorize(F,otypes=[float])(x)
Out[48]:
array([0. , 0.1025, 0.205 , 0.25 , 0.25 , 0.2625, 0.365 , 0.4675,
0.82 , 0.9225, 1.0 ])
and the same thing using a list comprehension:
In [49]: np.array([F(i) for i in x])
Out[49]:
array([0. , 0.1025, 0.205 , 0.25 , 0.25 , 0.2625, 0.365 , 0.4675,
0.82 , 0.9225, 1.0 ])
For this small x the list comprehension is faster; for your large x_range, vectorize is faster.
A "truely vectorized" calculation is:
def foo(x):
res = np.zeros(x.shape)
mask = (x>0) & (x<=100); res[mask] = 0.0025*x[mask]
mask = (x>100) & (x<=200); res[mask] = .25
mask = (x>200) & (x<=300); res[mask] = 0.0025*x[mask]-.25
mask = (x>300) & (x<=400); res[mask] = 0.0025*x[mask]
mask = (x>400); res[mask] = 1
return res
For my 10 element x is is slower, but for the large x_range scales much better.