I have a table with DDL as below in the Azure Synapse Data Warehouse:
CREATE TABLE [trans_customer_cdm_ejkb].[cdm_file_process_history]
(
[id] [int] IDENTITY(1,1) NOT NULL,
[layer] [varchar](500) NOT NULL,
[ingest_partition] [varchar](100) NULL,
[status] [varchar](25) NULL,
[last_update_time] [datetime2](7) NULL,
[pipeline_run_id] [varchar](200) NULL
)
WITH
(
DISTRIBUTION = HASH ( [ingest_partition] ),
CLUSTERED COLUMNSTORE INDEX
)
GO
I tried to append values into this table 3 times with the sql below, the id column has a seed value of 45 and incremental value of 60 inspite of the IDENTITY(1,1).
DECLARE @now DATETIME2 = GETDATE()
INSERT INTO trans_customer_cdm_ejkb.cdm_file_process_history
(layer, ingest_partition, [status], last_update_time, pipeline_run_id)
VALUES ('src2stg', '2022-02-18-03', 'success', @now, 'Test')
SELECT * FROM trans_customer_cdm_ejkb.cdm_file_process_history
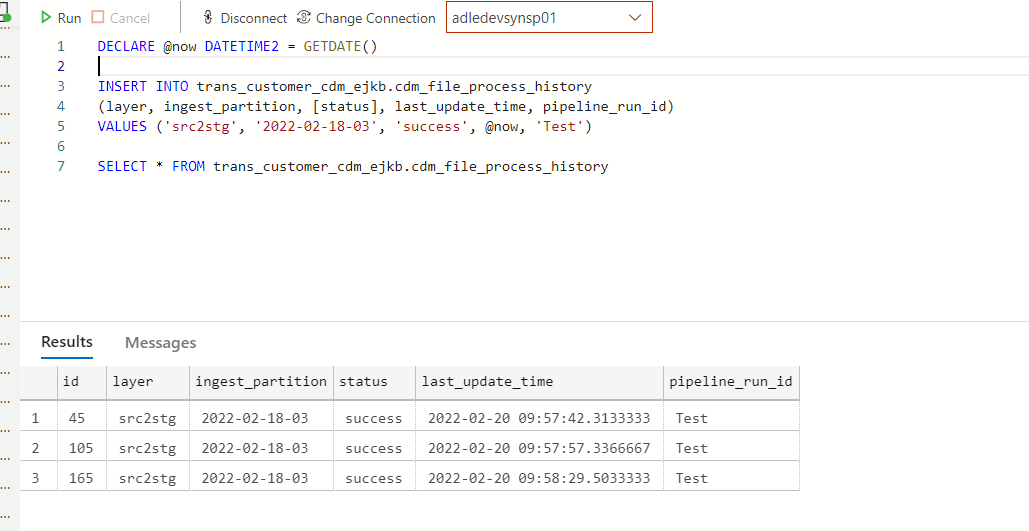 Also, I check the seed value as 1 and incremental value as 1 with the SQL below. However, the table does not provide the id value as expected
Also, I check the seed value as 1 and incremental value as 1 with the SQL below. However, the table does not provide the id value as expected
SELECT sm.name
, tb.name
, co.name
, ic.seed_value
, ic.increment_value
FROM sys.schemas AS sm
JOIN sys.tables AS tb ON sm.schema_id = tb.schema_id
JOIN sys.columns AS co ON tb.object_id = co.object_id
JOIN sys.identity_columns AS ic ON co.object_id = ic.object_id
AND co.column_id = ic.column_id
WHERE sm.name = 'trans_customer_cdm_ejkb'
AND tb.name = 'cdm_file_process_history'
;
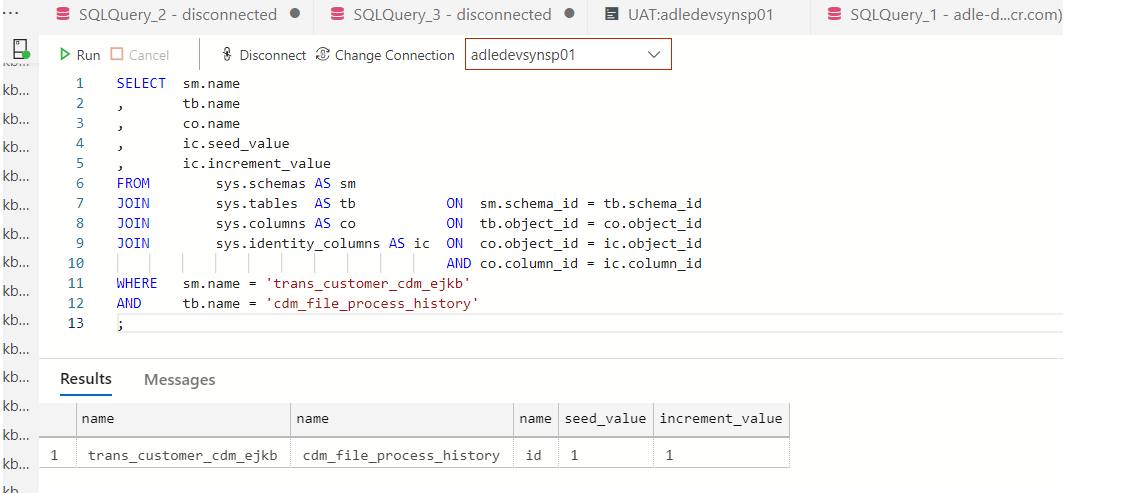
How can I fix this issue ?
Kind regards,
CodePudding user response:
IDENTITY columns in Azure Synapse Analytics dedicated SQL pools do guarantee unique values but do not guarantee sequential values. The reason is because data is split across 60 distributions; each distribution has a unique set of identity values.
If it's important for you to have a sequential column then recreate the table without the IDENTITY property and change your INSERT statement to the following code which will produce a sequential ID:
DECLARE @now DATETIME2 = GETDATE()
INSERT INTO trans_customer_cdm_ejkb.cdm_file_process_history
(id, layer, ingest_partition, [status], last_update_time, pipeline_run_id)
SELECT
(SELECT ISNULL(MAX(id),0) FROM trans_customer_cdm_ejkb.cdm_file_process_history) 1 as id,
'src2stg', '2022-02-18-03', 'success', @now, 'Test'
SELECT * FROM trans_customer_cdm_ejkb.cdm_file_process_history
Since your code was just inserting a single row I did 1 but normally you would do ROW_NUMBER() OVER (ORDER BY [SomeColumn]).