I'm new to elastic search.
So this is how the index looks:
{
"scresults-000001" : {
"aliases" : {
"scresults" : { }
},
"mappings" : {
"properties" : {
"callType" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"code" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"data" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"esdtValues" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"gasLimit" : {
"type" : "long"
},
AND MORE OTHER Fields.......
If I'm trying to create a search query in Java that looks like this:
{
"bool" : {
"filter" : [
{
"term" : {
"sender" : {
"value" : "erd1uw3z90sxvhq5z43nkk2qtc30uxsv3xtstvlz74f0taq6c50qg5usjy7h4a",
"boost" : 1.0
}
}
},
{
"term" : {
"data" : {
"value" : "YWRkTGlxdWlkaXR5UHJveHlAMDAwMDAwMDAwMDAwMDAwMDA1MDBlYmQzMDRjMmYzNGE2YjNmNmE1N2MxMzNhYjdiOGM2ZjgxZGM0MDE1NTQ4M0A3ZjE1YjEwODdmMjUwNzQ4QDBjMDU0YjcwNDhlMmY5NTE1ZWE3YWU=",
"boost" : 1.0
}
}
}
],
"adjust_pure_negative" : true,
"boost" : 1.0
}
}
If I run this query I get 0 hits. If I change the field "data" with other field it works. I don't understand what's different.
How I actually create the query in Java SprigBoot:
QueryBuilder boolQuery = QueryBuilders.boolQuery()
.filter(QueryBuilders.termQuery("sender", "erd1uw3z90sxvhq5z43nkk2qtc30uxsv3xtstvlz74f0taq6c50qg5usjy7h4a"))
.filter(QueryBuilders.termQuery("data",
"YWRkTGlxdWlkaXR5UHJveHlAMDAwMDAwMDAwMDAwMDAwMDA1MDBlYmQzMDRjMmYzNGE2YjNmNmE1N2MxMzNhYjdiOGM2ZjgxZGM0MDE1NTQ4M0A3ZjE1YjEwODdmMjUwNzQ4QDBjMDU0YjcwNDhlMmY5NTE1ZWE3YWU="));
Query searchQuery = new NativeSearchQueryBuilder()
.withFilter(boolQuery)
.build();
SearchHits<ScResults> articles = elasticsearchTemplate.search(searchQuery, ScResults.class);
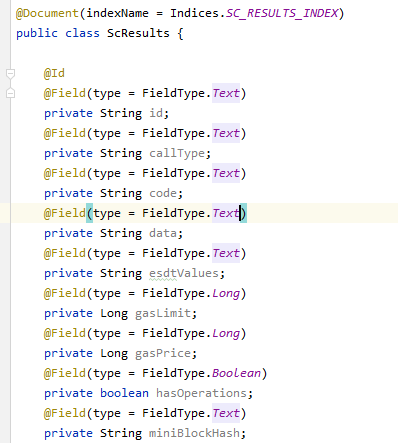
How the model for ScResults looks:
Document:
CodePudding user response:
Since you're trying to do an exact match on a string with a term query, you need to do it on the data.keyword field which is not analyzed. Since the data field is a text field, hence analyzed by the standard analyzer, not only are all letters lowercased but the = sign at the end also gets stripped off, so there's no way this can match (unless you use a match query on the data field but then you'd not do exact matching anymore).
POST _analyze
{
"analyzer": "standard",
"text": "YWRkTGlxdWlkaXR5UHJveHlAMDAwMDAwMDAwMDAwMDAwMDA1MDBlYmQzMDRjMmYzNGE2YjNmNmE1N2MxMzNhYjdiOGM2ZjgxZGM0MDE1NTQ4M0A3ZjE1YjEwODdmMjUwNzQ4QDBjMDU0YjcwNDhlMmY5NTE1ZWE3YWU="
}
Results:
{
"tokens" : [
{
"token" : "ywrktglxdwlkaxr5uhjvehlamdawmdawmdawmdawmdawmda1mdblymqzmdrjmmyznge2yjnmnme1n2mxmznhyjdiogm2zjgxzgm0mde1ntq4m0a3zje1yjewoddmmjuwnzq4qdbjmdu0yjcwndhlmmy5nte1zwe3ywu",
"start_offset" : 0,
"end_offset" : 163,
"type" : "<ALPHANUM>",
"position" : 0
}
]
}