I'm getting below this issue in GKS Pod is blocking scale down because it's a non-daemonset, non-mirrored, non-pdb-assigned kube-system pod
I have read this docs :-
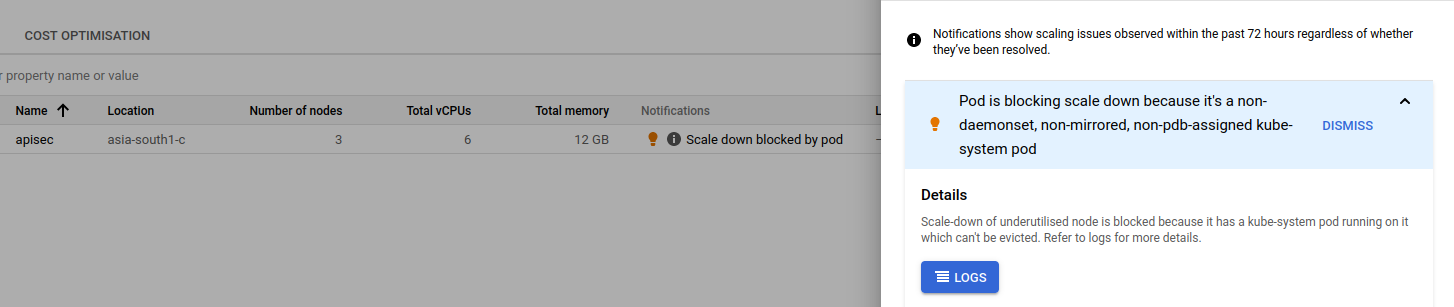

Please tell me how to solve that error/issue in GKS from 3 days im not able to understand and solve it even i google it and ready so many website but didnt solve it.
After deploying
kubectl create poddisruptionbudget pdb --namespace=kube-system --selector k8s-app=kube-dns --max-unavailable 1
Warning: policy/v1beta1 PodDisruptionBudget is deprecated in v1.21 , unavailable in v1.25 ; use policy/v1 PodDisruptionBudget
poddisruptionbudget.policy/pdb created
I Got deprecated and another issue
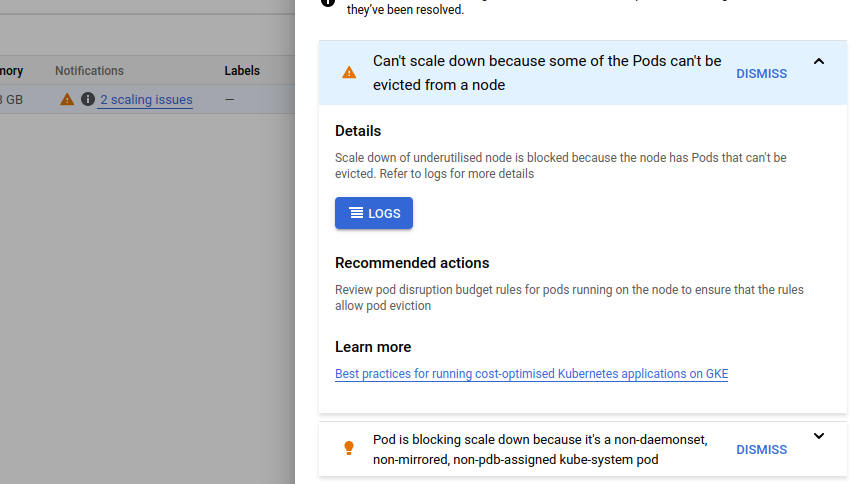
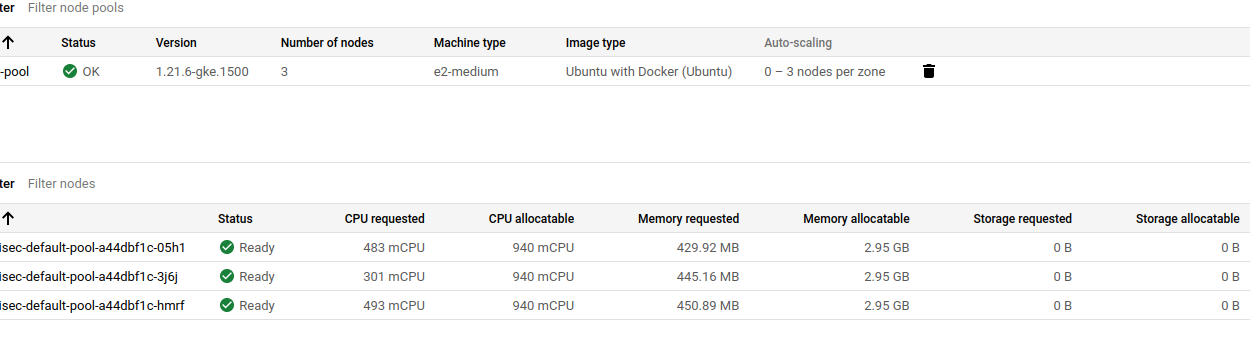
Previous i was having 3 nodes but i have 2 nodes only now because i have edit one node remove this line "cluster-autoscaler.kubernetes.io/scale-down-disabled": "true" which i have added in it after that i didnt check whether my nodes are 3 or 2.
Later i check found only 2 nodes are running.
Its a good or bad to edit nodes in GKE or AKS
kubectl get pdb -A
NAMESPACE NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE
kube-system kube-dns-bbc N/A 1 1 69m
Here is yaml file
kubectl get pdb kube-dns-bbc -o yaml -n kube-system
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"policy/v1","kind":"PodDisruptionBudget","metadata":{"annotations":{},"labels":{"k8s-app":"kube-dns"},"name":"kube-dns-bbc","namespace":"kube-system"},"spec":{"maxUnavailable":1,"selector":{"matchLabels":{"k8s-app":"kube-dns"}}}}
creationTimestamp: "2022-02-18T17:07:53Z"
generation: 1
labels:
k8s-app: kube-dns
name: kube-dns-bbc
namespace: kube-system
resourceVersion: "230860"
uid: 7131c64d-6779-4b23-8c53-10ffcc242144
spec:
maxUnavailable: 1
selector:
matchLabels:
k8s-app: kube-dns
status:
conditions:
- lastTransitionTime: "2022-02-18T17:38:13Z"
message: ""
observedGeneration: 1
reason: SufficientPods
status: "True"
type: DisruptionAllowed
currentHealthy: 2
desiredHealthy: 1
disruptionsAllowed: 1
expectedPods: 2
observedGeneration: 1
CodePudding user response:
I have read this docs :- https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/FAQ.md#how-to-set-pdbs-to-enable-ca-to-move-kube-system-pods
but still not able to understand where i need to add this line in every pods or every nodes. if pods which i need to add.
You don't add to pod or node, you need to create PDB for pod in kube-system so that CA knows it is safe to evict such pods from the node that is suppose to be remove. Example for coreDNS:
kubectl create poddisruptionbudget <name> --namespace=kube-system --selector k8s-app=kube-dns --max-unavailable 1
CodePudding user response:
In the link that you share it is stated:
By default, kube-system pods prevent CA from removing nodes on which they are running. Users can manually add PDBs for the kube-system pods that can be safely rescheduled elsewhere:
kubectl create poddisruptionbudget <pdb name> --namespace=kube-system --selector app=<app name> --max-unavailable 1
A PDB limits the number of Pods of a replicated application that are down simultaneously from voluntary disruptions. For example, a quorum-based application would like to ensure that the number of replicas running is never brought below the number needed for a quorum
You can find more information about disruptions here.
Specifying a Disruption Budget for your Application here .
Also a complete tutorial about Pod Disruption Budget for helping manually upgrading GKE Cluster.
What types of pods can prevent CA from removing a node?
Pods with restrictive PodDisruptionBudget.
Kube-system pods that:
- are not run on the node by default, *
- don't have a pod disruption budget set or their PDB is too restrictive (since CA 0.6).
- Pods that are not backed by a controller object (so not created by deployment, replica set, job, stateful set etc). *
- Pods with local storage. *
- Pods that cannot be moved elsewhere due to various constraints (lack of resources, non-matching node selectors or affinity, matching anti-affinity, etc)
Pods that have the following annotation set:
- "cluster-autoscaler.kubernetes.io/safe-to-evict": "false"
- *Unless the pod has the following annotation (supported in CA 1.0.3 or later):
- "cluster-autoscaler.kubernetes.io/safe-to-evict": "true"
Or you have overridden this behavior with one of the relevant flags. See below for more information on these flags.
You can use Autoscaler events to review your pods, and see which one is causing the blocking of the CA to downscale.
Adding to this, you can find this answer in another question to solve more doubts that you can have.