I am trying to use BeautifulSoup and requests to scrape the table 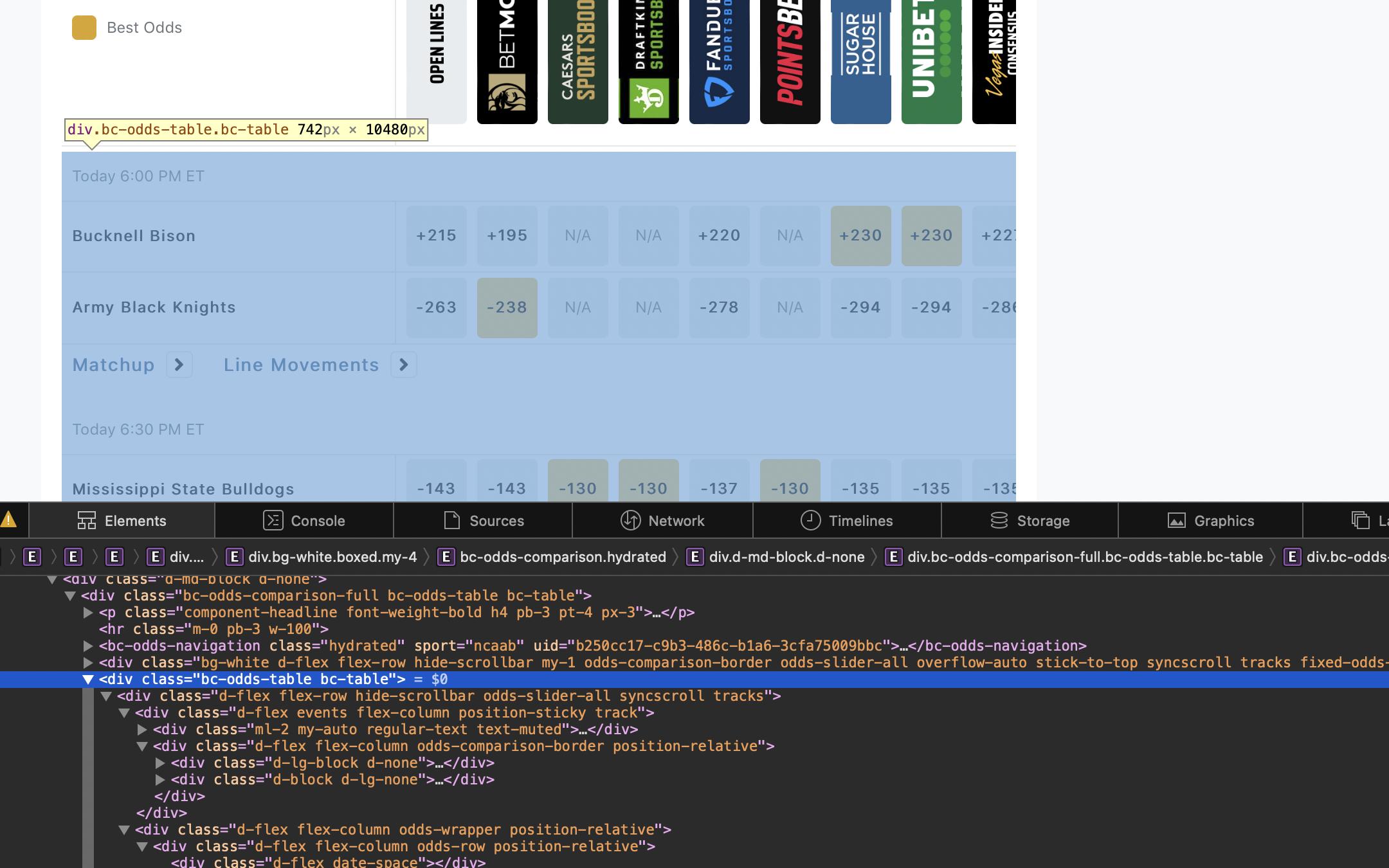
I was also able to get something by doing this:
data = [[x.text for x in y.findAll('div')] for y in divList]
df = pd.DataFrame(data)
print(df)
[1 rows x 5282 columns]
How would I be able to loop through these divs and return the data in a pandas dataframe?
When using div.text, it returns one long string of the data that I want. I could split this string up into many pieces and glue it into a df where I want it to go. But that seems like a hack job at best.
CodePudding user response:
You basically need to go through all the divs by identifying unique identifiers in the class names. Try this:
import pandas as pd
import requests
from bs4 import BeautifulSoup
def extract_data_from_div(div):
# contains the names of the teams
left_side_div = div.find('div', class_='d-flex flex-column odds-comparison-border position-relative')
name_data = []
for name in left_side_div.find_all('div', class_='team-stats-box'):
name_data.append(name.text.strip())
# to save all the extracted odds
odds = []
# now isolate the divs with the odds
for row in div.find_all('div', class_='px-1'):
# all the divs for each bookmaker
odds_boxes = row.find_all('div', class_='odds-box')
odds_box_data = []
for odds_box in odds_boxes:
# sometimes they're just 'N/A' so this will stop the code breaking
try:
pt_2 = odds_box.find('div', class_='pt-2').text.strip()
except:
pt_2 = ''
try:
pt_1 = odds_box.find('div', class_='pt-1').text.strip()
except:
pt_1 = ''
odds_box_data.append((pt_2, pt_1))
# append to the odds list
odds.append(odds_box_data)
# put the names and the odds together
extracted_data = dict(zip(name_data, odds))
return extracted_data
url = "https://www.vegasinsider.com/college-basketball/odds/las-vegas/"
resp = requests.get(url)
soup = BeautifulSoup(str(resp.text), "html.parser")
# this will give you a list of each set of match odds
div_list = soup.find_all('div', class_='d-flex flex-row hide-scrollbar odds-slider-all syncscroll tracks')
data = {}
for div in div_list:
extracted = extract_data_from_div(div)
data = {**data, **extracted}
# finally convert to a dataframe
df = pd.DataFrame.from_dict(data, orient='index').reset_index()