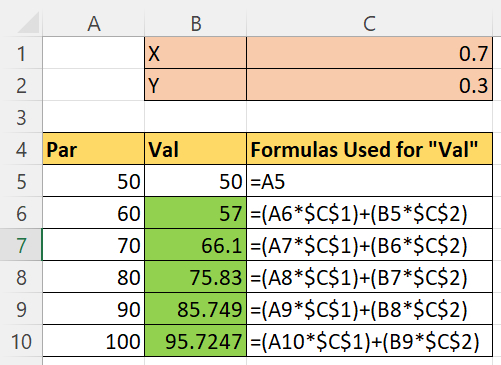
The cells highlighted in Green are the calculations that need to be done in pandas dataframe without the application for for loop.
i tried the below code. But it is giving wrong values in column "Val".
The Obtained output from the code is
DataFrame: df Par Val 0 50 50.0 1 60 57.0 2 70 67.0 3 80 77.0 4 90 87.0 5 100 97.0
Need help in getting the values as shown in image without loop application. [![enter image description here][2]][2]
[![enter image description here][2]][2]
df = pd.DataFrame()
df['Par'] = [50,60,70,80,90,100]
k = df['Par'].shift(1).fillna(df['Par'][0]).astype(float)
df['Val'] = (df['Par']*0.7) (k*0.3)
print("DataFrame: df\n",df)`
CodePudding user response:
Recursive calculations are not vectorisable, for improve performance is used numba:
from numba import jit
@jit(nopython=True)
def f(a):
d = np.empty(a.shape)
d[0] = a[0]
for i in range(1, a.shape[0]):
d[i] = d[i-1] * 0.3 a[i] * 0.7
return d
df['Val'] = f(df['Par'].to_numpy())
print (df)
Par Val
0 50 50.0000
1 60 57.0000
2 70 66.1000
3 80 75.8300
4 90 85.7490
5 100 95.7247
Difference for performance for 1k rows:
from numba import jit
import itertools
np.random.seed(2022)
df = pd.DataFrame({'Par': np.random.randint(100, size=1000)})
In [64]: %%timeit
...:
...: df['Val1'] = f(df['Par'].to_numpy())
...:
...: import itertools
...:
...: df.loc[0,"Val"] = df.loc[0,"Par"]
...: for _ in itertools.repeat(None, len(df)):
...: df["Val"] = df["Val"].fillna((df["Par"]*0.7) (df["Val"].shift(1)*(0.3)))
...:
1.05 s ± 193 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
In [65]: %%timeit
...: @jit(nopython=True)
...: def f(a):
...: d = np.empty(a.shape)
...: d[0] = a[0]
...: for i in range(1, a.shape[0]):
...: d[i] = d[i-1] * 0.3 a[i] * 0.7
...: return d
...:
...: df['Val1'] = f(df['Par'].to_numpy())
...:
121 ms ± 3.23 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
Test for 100krows:
np.random.seed(2022)
df = pd.DataFrame({'Par': np.random.randint(100, size=100000)})
In [70]: %%timeit
...:
...: df['Val1'] = f(df['Par'].to_numpy())
...:
...: import itertools
...:
...: df.loc[0,"Val"] = df.loc[0,"Par"]
...: for _ in itertools.repeat(None, len(df)):
...: df["Val"] = df["Val"].fillna((df["Par"]*0.7) (df["Val"].shift(1)*(0.3)))
...:
4min 47s ± 5.39 s per loop (mean ± std. dev. of 7 runs, 1 loop each)
In [71]: %%timeit
...: @jit(nopython=True)
...: def f(a):
...: d = np.empty(a.shape)
...: d[0] = a[0]
...: for i in range(1, a.shape[0]):
...: d[i] = d[i-1] * 0.3 a[i] * 0.7
...: return d
...:
...: df['Val1'] = f(df['Par'].to_numpy())
...:
...:
129 ms ± 11.5 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
CodePudding user response:
I am not sure if this answer will be good enough. First, the reason your code does not work similar to Excel is that Excel is using cummulative calculation, which means k value is updated from the result of the formula with the value in df["par"] and previous row of k. The nature of the problem itself has to be solved by using previous row; which means row by row.
How to achieve this is easy.
import pandas as pd
df = pd.DataFrame()
df['Par'] = [50,60,70,80,90,100]
df.loc[0,"Val"] = df.loc[0,"Par"] #similar to =A5 in excel
Par Val
0 50 50.0
1 60 NaN
2 70 NaN
3 80 NaN
4 90 NaN
5 100 NaN
The concept is that the na value will be filled with the calculation from the previous row and same row different. But the third, fourth and fifth rows are do not have previous values to be calculated, SO, they will be filled with na again.
df["Val"] = df["Val"].fillna((df["Par"]*0.7) (df["Val"].shift(1)*(0.3)))
Par Val
0 50 50.0
1 60 57.0
2 70 NaN
3 80 NaN
4 90 NaN
5 100 NaN
After we have imputed the second row of Val, the third row now have a previous value to impute itself with. So, we run the line again.
Par Val
0 50 50.0
1 60 57.0
2 70 66.1
3 80 NaN
4 90 NaN
5 100 NaN
So, the same now for the fourth, then the fifth. But when you have more than 5 rows, it would be a chore for you to be running this line again and again. So, in this kind of situation, we would use (yes) a loop. But your request includes without Using for loop portion, which I am out of my wits. There probably are ways to do so, but for me, I am stuck on calculate -> get value -> calculate. So, here are a couple of loops, that do not use any data from the dataframe itself, but just repeat code for a number of times instead.
i == 0
if i < len(df):
df["Val"]=df["Val"].fillna((df["Par"]*0.7) (df["Val"].shift(1)*(0.3)))
i
for i in range(len(df)):
df["Val"]=df["Val"].fillna((df["Par"]*0.7) (df["Val"].shift(1)*(0.3)))
i
import itertools
for _ in itertools.repeat(None, len(df)):
df["Val"] = df["Val"].fillna((df["Par"]*0.7) (df["Val"].shift(1)*(0.3)))
Please share with us, when you have figured out a way to do so without using a loop. I've had a very interesting evening today, thanks to you.