Hello i need help with this particular site:(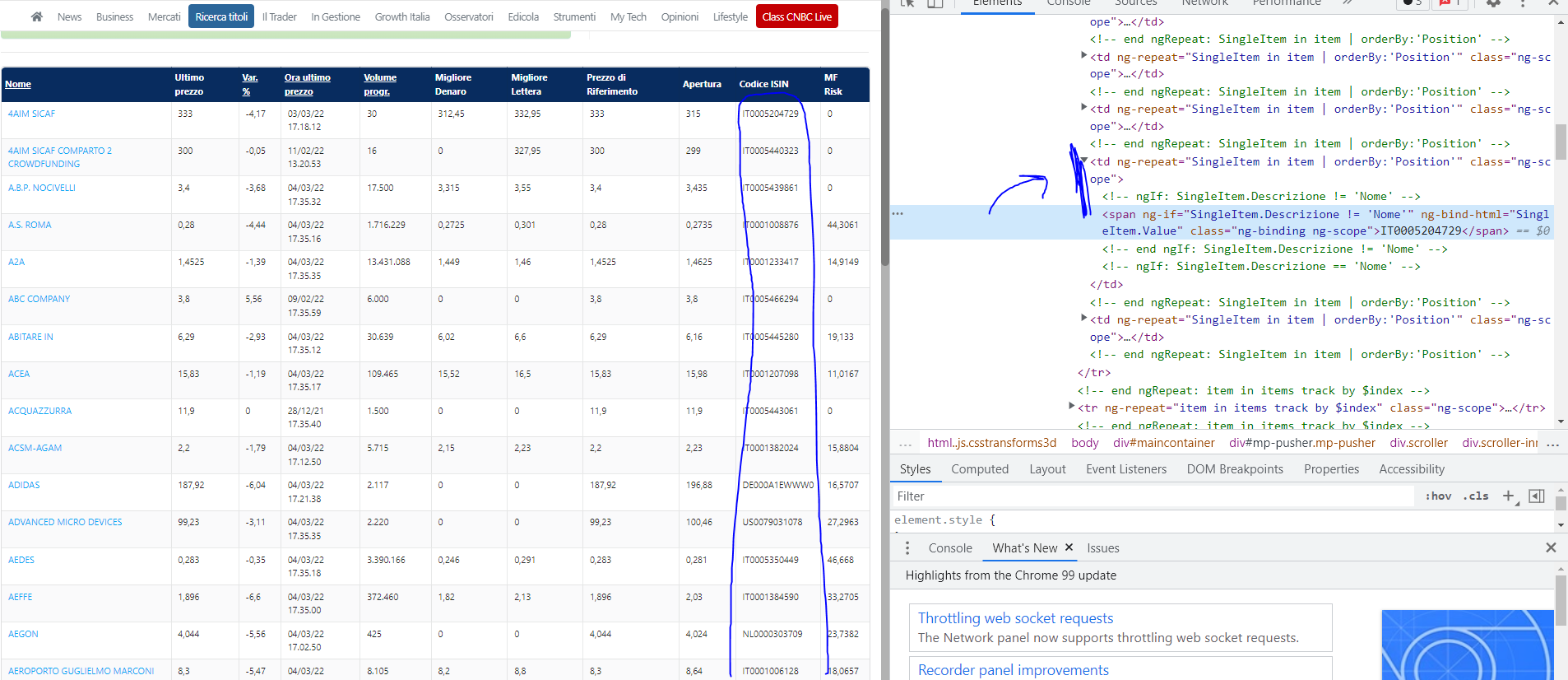
Isin:
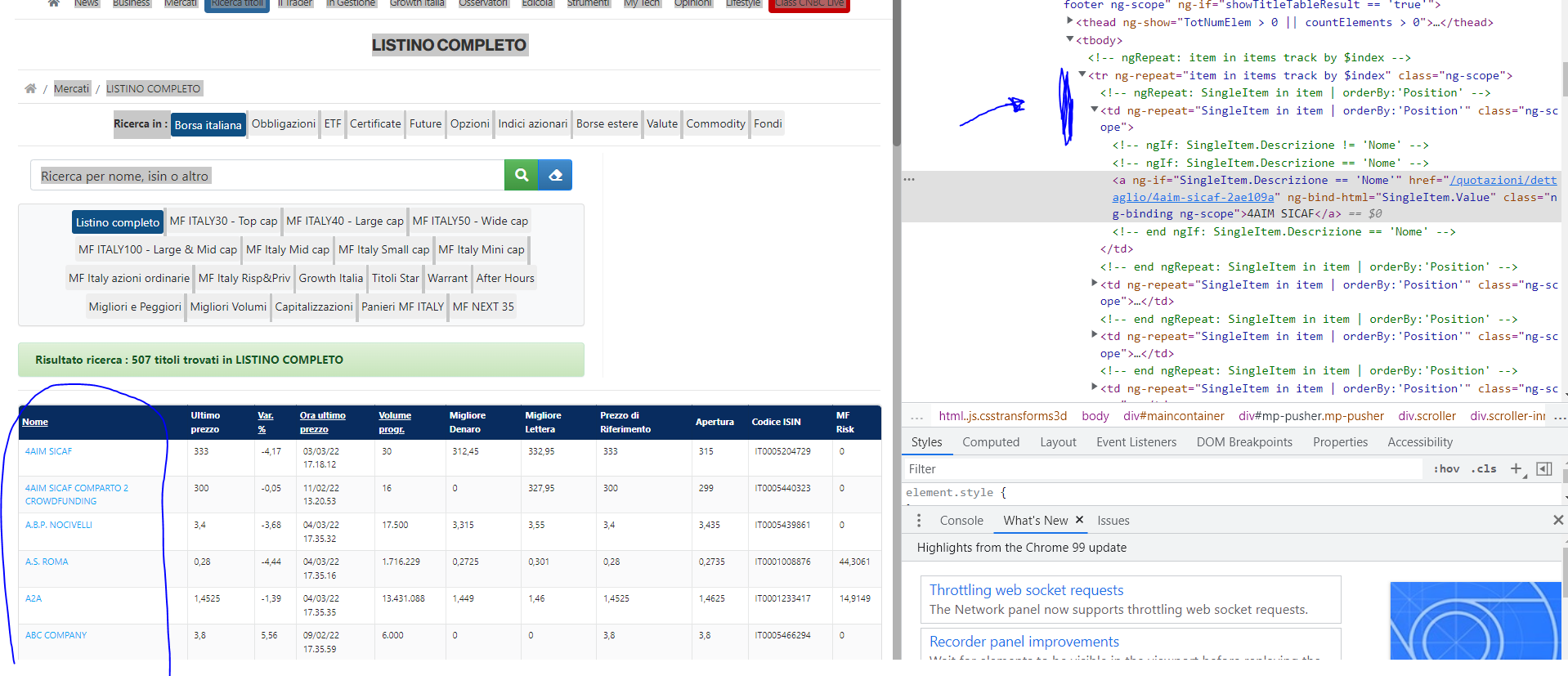
CodePudding user response:
I'm sorry, but I can't see how your existing code is working.
On my side I see the locator you are using for isin matching nothing.
I have updated locators here.
I would advice you never using automatically created locators.
Also the code you presenting here is missing indentations. I hope your actual code having proper indentations.
Please see if this will work better:
wd = wd.Chrome()
wd.get('https://www.milanofinanza.it/quotazioni/ricerca/listino-completo-2ae')
company_name = []
isin = []
for n in range(0,15):
time.sleep(10)
tickers = wd.find_elements(By.XPATH,"//table[contains(@class,'celled')]//tbody//tr//td[1]")
isins = wd.find_elements(By.XPATH,"//table[contains(@class,'celled')]//tbody//tr//td[10]")
for el in tickers:
company_name.append(el.text)
for is_el in isins:
isin.append(is_el.text)
l=wd.find_element(By.XPATH,'//nav//button[@ng-click="getDataTableNextClick()"]')
wd.execute_script("arguments[0].click();",l)
CodePudding user response:
My first instinct is to tell you that selenium is probably a little bloated for what you're doing. There are times when you need a full-fledged browser, but this isn't one of them. I'd recommend requests and beautiful soup (it's more suited to making a shit load of requests.) I appreciate that you were running javascript to get more items (although for me, the reloading button wasn't doing anything) In that case, it is necessary. But, I source viewed the website to discover that the data you want can be retrieved in JSON format (so no need for BS) and in a simple get request.
import requests
data = requests.get("https://www.milanofinanza.it/Mercati/GetDataTabelle?alias=&campoOrdinamento=0002&numElem=30&ordinamento=asc&page=4&url=listino-completo-2ae?refresh_cens")
print(data.text)
Or do it like this so it's easier to adjust the params:
def pack(**kwargs):
return kwargs
data2 = requests.get("https://www.milanofinanza.it/Mercati/GetDataTabelle", params=pack(alias="",campoOrdinamento="0002",numElem=30,ordinamento="asc",page=4,url="listino-completo-2ae",refresh_cens=""))
I'm out of time; if I got the wrong data, LMK, and I'll correct the answer.