I have a pandas dataframe that I want to group by and create columns for each value of col1 and they should contain the value of col2. And example dataframe:
data = {'item_id': {0: 2, 1: 2, 2: 2, 3: 3, 4: 3},
'feature_category_id': {0: 56, 1: 62, 2: 68, 3: 56, 4: 72},
'feature_value_id': {0: 365, 1: 801, 2: 351, 3: 802, 4: 75}}
df = pd.DataFrame(data)
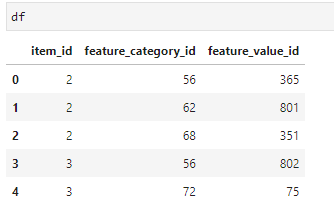
I want to groupby item_id, create as many columns as feature_category_id and fill them with the feature_value_id.
The resultant df for the example would look like this:
data = {'item_id': {0: 2, 1: 3},
'feature_56': {0: 801, 1: 802},
'feature_62': {0: 365, 1: None},
'feature_68': {0: 351, 1: None},
'feature_72': {0: None, 1: 75},}
df = pd.DataFrame(data)
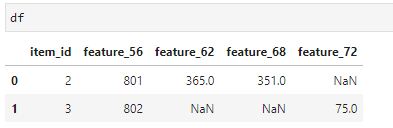
Where features not present for a certain item_id (but present for at least one item_id) are NaN.
Which would be the most optimal operation to do this?
CodePudding user response:
What you are searching for is pandas pivot() function. It does exactly what you want:
# Change df shape
result = df.pivot(index="item_id", columns="feature_category_id")
# Change the axis labels
result.columns = ["feature_" str(x[1]) for x in result.columns]
result = result.reset_index()
Output:
item_id feature_56 feature_62 feature_68 feature_72
0 2 365.0 801.0 351.0 NaN
1 3 802.0 NaN NaN 75.0