Sample dataframe:
import pandas as pd
df1 = pd.DataFrame({'date': ['2022-02-25','2022-02-26','2022-02-25'],
'attempt_1':[1,0,0],
'attempt_2':[0,0,1],
'attempt_3':[1,1,0]})
df1
The following code takes 1hr 30mins to process about 252k rows and 75 columns. Unfortunately, that is too long and I don't know if there is any method out there that can replace(?) this to reduce the processing time.
dategrp = set(df1["date"])
dfs_to_dategrp = []
for trial in df1.columns[:]:
save_sf = {k:{"success":0, "fail":0} for k in dategrp}
for c in dategrp:
save_sf[c]["success"] = len(df1[(df1["date"]==c) & (df1[trial]==1)])
save_sf[c]["fail"] = len(df1[(df1["date"]==c) & (df1[trial]==0)])
new_df1 = pd.DataFrame(save_sf)
new_df1 = new_df1.T
dfs_to_dategrp.append(new_df1)
result= pd.concat(dfs_to_dategrp, axis = 1)
result
So in the dataframe, the columns are populated randomly with 1s (success) and 0s (fail). This code goes through each rows and columns (this method is too long) to group and total the 1s and 0s to the date of occurence.
Here is the output
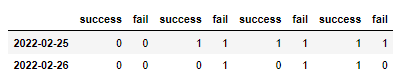
Any help given will be appreciated. Thanks.
CodePudding user response:
Just a hunch: If your dataframe df1 looks somehow like
df1 = pd.DataFrame(
{"date": ["2022-03-09", "2022-03-09", "2022-03-10"],
"trial_1": [1, 0, 1], "trial_2": [1, 1, 1], "trial_3": [0, 0, 0]}
)
df1.date = pd.to_datetime(df1.date)
date t_1 t_2 t_3
0 2022-03-09 1 1 0
1 2022-03-09 0 1 0
2 2022-03-10 1 1 0
then you could use .groupby and .agg do something like
def success(ser): return ser.sum()
def failure(ser): return ser.eq(0).sum()
result = df1.groupby("date").agg(**{
**{f"{col}_success": (col, success) for col in df1.columns if col != "date"},
**{f"{col}_failure": (col, failure) for col in df1.columns if col != "date"}
})
to get a result like
t_1_success t_2_success t_3_success t_1_failure t_2_failure \
date
2022-03-09 1 2 0 1 0
2022-03-10 1 1 0 0 0
t_3_failure
date
2022-03-09 2
2022-03-10 1
or
result = df1.groupby("date").agg(
**dict(col
for pair in [[(f"{c}_success", (c, success)), (f"{c}_failure", (c, failure))]
for c in df1.columns if c != "date"]
for col in pair
)
)
to get
t_1_success t_1_failure t_2_success t_2_failure t_3_success \
date
2022-03-09 1 1 2 0 0
2022-03-10 1 0 1 0 0
t_3_failure
date
2022-03-09 2
2022-03-10 1
Another option:
result_1 = df1.assign(length=1).groupby("date").sum()
result_2 = result_1.rsub(result_1["length"], axis=0)
result = pd.concat(
[result_1
.drop(columns="length")
.rename(columns={c: f"{c}_success" for c in result_1.columns}),
result_2
.drop(columns="length")
.rename(columns={c: f"{c}_failure" for c in result_2.columns})],
axis=1
)