Hello I want to create a new column from a given dataset (that I call here "df") with the first non-Nan for each row and closest from a given column
For example, I have a data frame with the years 2009 2010 2011 2012 2013. I want to find the first Non-Nan value for each row but starting from year 2011!
So here's a given dataset that I would col "indicator"
import pandas as pd
import numpy as np
data = np.random.randn(6,6)
mask = np.random.choice([1, 0], data.shape, p=[.1, .9]).astype(bool)
data[mask] = np.nan
df = pd.DataFrame(data=data,columns=['2009','2010','2011','2012','2013','2014'])
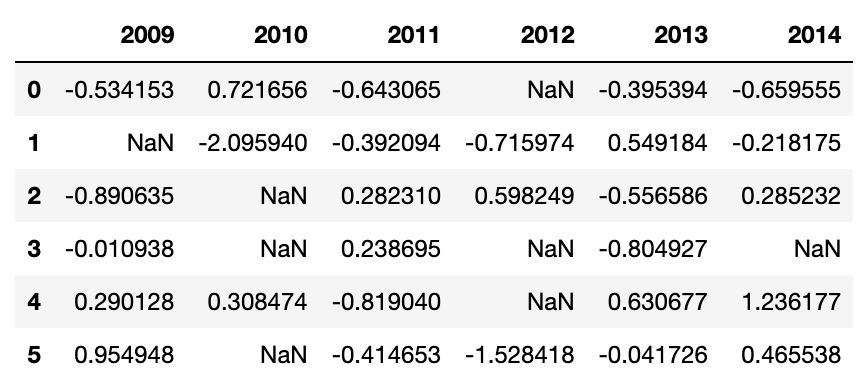
df
which output
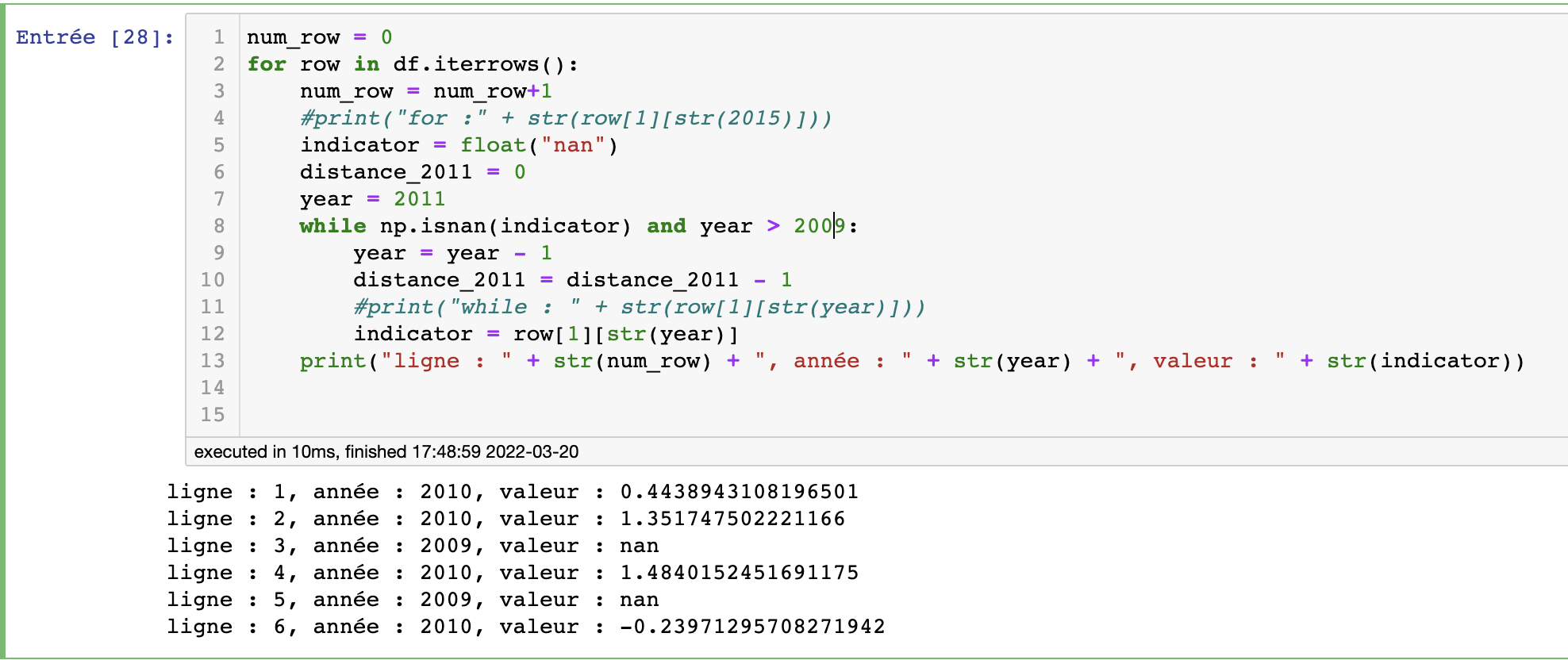
I started to write the following function which gives the first non-NaN values from 2011 to 2009 for each row:
num_row = 0
for row in df.iterrows():
num_row = num_row 1
#print("for :" str(row[1][str(2015)]))
indicator = float("nan")
distance_2011 = 0
year = 2011
while np.isnan(indicator) and year > 2009:
year = year - 1
distance_2011 = distance_2011 - 1
#print("while : " str(row[1][str(year)]))
indicator = row[1][str(year)]
print("ligne : " str(num_row) ", année : " str(year) ", valeur : " str(indicator))
)
This output the first non-NaN value from 2011 to 2009, it's value and column year.
But this does not add a new column to my dataset nor help me with the years from 2011 to 2014
Anyone here knows how to solve this? I want the closest non Nan from year 2011 for each row and add it to a new column :) Many Thanks!
CodePudding user response:
You can use this solution
df.loc[:, "new_col"] = df.apply(lambda x: x.loc['2011':].dropna()[0] if x.loc['2011':].dropna().shape[0]>0 else np.nan, axis=1)
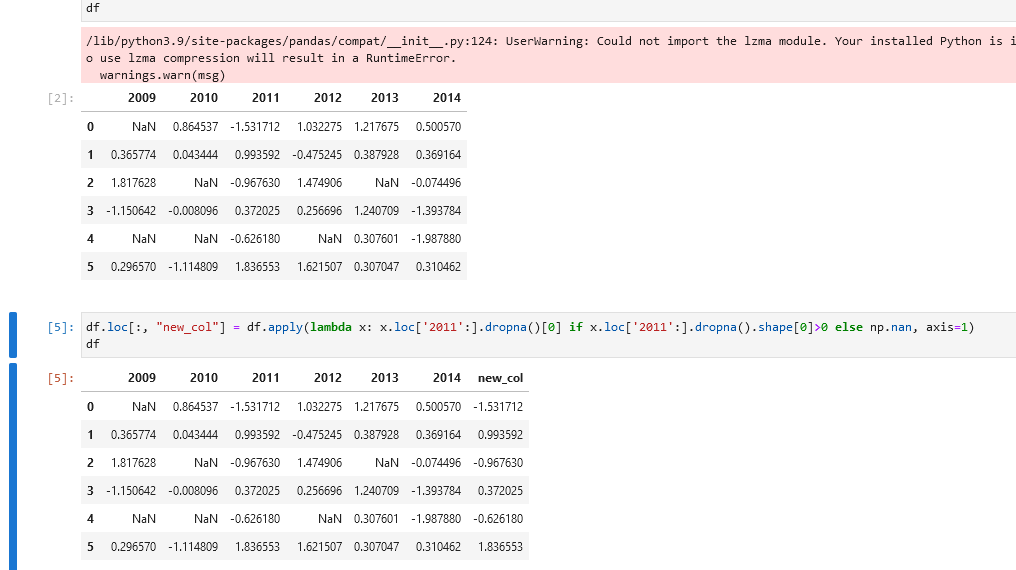
Hope this helps!
CodePudding user response:
IIUC:
df['value'] = df.loc[:, '2011':].bfill(axis=1)['2011']
print(df)
# Output
2009 2010 2011 2012 2013 2014 value
0 1.0 2.0 3.0 4.0 5.0 6.0 3.0
1 1.0 2.0 NaN 4.0 5.0 6.0 4.0
2 1.0 2.0 NaN NaN 5.0 6.0 5.0
3 1.0 2.0 NaN NaN NaN 6.0 6.0
4 1.0 2.0 NaN NaN NaN NaN NaN
Or more straightforward: df.bfill(axis=1)['2011']