I am trying to sum together content_len that are entered into the database a few seconds apart (colour coded). The table currently breaks into a new row once the character count hits 999, and inserts each overflow a few seconds apart. Due to errors, the overflow can be timestamped earlier than the previous body.
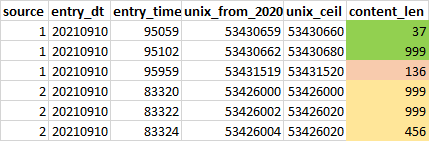
My current attempt is to round the timestamp to unix seconds, but issues occur when the rounding (unix_ceil) does not produce the same number for content that are to be grouped together. How can I ensure that entries that are within ~20 seconds of each other are summed together? Usually there is a separation of at least a few minutes between distinct records that are not to be grouped together (e.g. 999 37 at ~0950am and then 136 at ~0959am for source = 1).
SELECT source
,entry_dt
,SUM(content_len) AS full_length
FROM (
SELECT source
,entry_dt
,entry_time
,(TO_DATE(CONCAT(entry_dt, entry_time), 'yyyymmddHH24MISS') - TO_DATE('2020-01-01 00:00:00', 'YYYY-MM-DD HH24:MI:SS')) * 86400 AS unix_from_2020
,CEIL(86400 * (TO_DATE(CONCAT(entry_dt, entry_time), 'yyyymmddHH24MISS') - TO_DATE('2020-01-01 00:00:00', 'YYYY-MM-DD HH24:MI:SS')) / 20) * 20 AS unix_ceil -- round to 20 seconds
,content_len
FROM schema.text_length_records
) s
GROUP BY source, entry_dt, unix_ceil
CodePudding user response:
Do not store dates and times separately and do not store them in non-DATE data types. In Oracle a DATE is a binary data type consisting of 7 bytes which contain the components century, year-of-century, month, day, hour, minute and second and it ALWAYS has those components and is NEVER stored in any particular format.
You can then use a single DATE column to store both date and time and do it more efficiently and with better error checking than if you store the values separately as strings or numbers.
From Oracle 12, you can use MATCH_RECOGNIZE to do row-by-row processing.
If you want each row to be within 20 seconds of the previous row then:
SELECT *
FROM (
SELECT source,
TO_DATE(entry_dt || LPAD(entry_time, '0', 6), 'YYYYMMDDHH24MISS') AS entry_dt,
content_len
FROM text_length_records
)
MATCH_RECOGNIZE(
PARTITION BY source
ORDER BY entry_dt
MEASURES
FIRST(entry_dt) AS start_entry_dt,
LAST(entry_dt) AS end_entry_dt,
SUM(content_len) AS content_len
ONE ROW PER MATCH
PATTERN (within_20* last_time)
DEFINE
within_20 AS entry_dt INTERVAL '20' SECOND >= NEXT(entry_dt)
)
If you want each row to be within 20 seconds of the first row of the group then:
SELECT *
FROM (
SELECT source,
TO_DATE(entry_dt || LPAD(entry_time, 6, '0'), 'YYYYMMDDHH24MISS') AS entry_dt,
content_len
FROM text_length_records
)
MATCH_RECOGNIZE(
PARTITION BY source
ORDER BY entry_dt
MEASURES
FIRST(entry_dt) AS start_entry_dt,
LAST(entry_dt) AS end_entry_dt,
SUM(content_len) AS content_len
ONE ROW PER MATCH
PATTERN (within_20*)
DEFINE
within_20 AS entry_dt <= FIRST(entry_dt) INTERVAL '20' SECOND
)
Which, for the sample data:
CREATE TABLE text_length_records (source, entry_dt, entry_time, content_len) AS
SELECT 1, 20210910, 95059, 37 FROM DUAL UNION ALL
SELECT 1, 20210910, 95102, 999 FROM DUAL UNION ALL
SELECT 1, 20210910, 95959, 139 FROM DUAL UNION ALL
SELECT 2, 20210910, 83320, 999 FROM DUAL UNION ALL
SELECT 2, 20210910, 83322, 999 FROM DUAL UNION ALL
SELECT 2, 20210910, 83324, 456 FROM DUAL;
Both output:
SOURCE START_ENTRY_DT END_ENTRY_DT CONTENT_LEN 1 2021-09-10 09:50:59 2021-09-10 09:51:02 1036 1 2021-09-10 09:59:59 2021-09-10 09:59:59 139 2 2021-09-10 08:33:20 2021-09-10 08:33:24 2454
Note: Although the queries produce the same output for your sample data, they will produce slightly different outputs if you did have any sample data where the 3th row was not within 20 seconds of the 1st row of the group but was within 20 seconds of the 2nd row of the group.
db<>fiddle here