I am using Teradata 16.20.53.13 and have a table (minimized version):
CREATE TABLE TABLE_1
(
std_nm VARCHAR(50),
std_age INTEGER
);
With data (minimum subset):
insert into TABLE_1 values ('abc', 31);
insert into TABLE_1 values ('abc', 36);
insert into TABLE_1 values ('abc', 35);
insert into TABLE_1 values ('xyz', 17);
insert into TABLE_1 values ('xyz', 14);
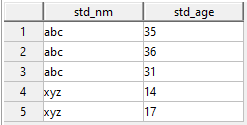
What I want is to have count, sum and average of std_age only for last unique value of std_nm.
One approach I followed gives me desired result but with count, sum and average in all rows:
select t1.std_nm,
t1.std_age,
t2.name_count,
t2.sum_age,
t2.avg_age
from TABLE_1 as t1
inner join (
select std_nm,
count(std_nm) as name_count,
sum(std_age) as sum_age,
avg(std_age) as avg_age
from TABLE_1
group by std_nm
) t2
on t1.std_nm = t2.std_nm
order by t1.std_nm;
With above SQL my result looks like:
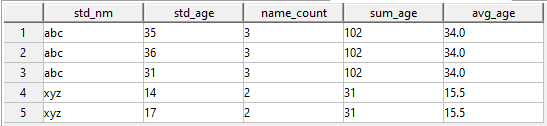
Question: How can I get result with zero/null/blank in name_count, sum_age and avg_age for all unique values of std_nm except the last one. So result I am looking for is:
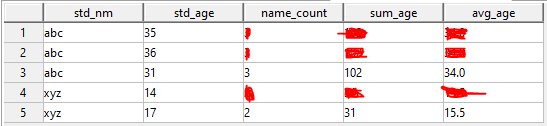
I am trying to use CASE while selecting name_count, sum_age and avg_age but I think there might be a better/cleaner way to do this. Maybe by using join in smarter way or something else. I am open to all options that work on Teradata 16.
CodePudding user response:
SELECT D.std_nm,D.std_age,D.XCOL,
CASE
WHEN D.XCOL=1 THEN SUB_Q.avg_age
ELSE NULL
END AS AVG_AGE,
CASE
WHEN D.XCOL=1 THEN SUB_Q.name_count
ELSE NULL
END AS NAME_COUNT,
CASE
WHEN D.XCOL=1 THEN SUB_Q.sum_age
ELSE NULL
END AS SUM_AGE
FROM
(
SELECT T.std_nm,T.std_age,
ROW_NUMBER()OVER (PARTITION BY T.std_nm ORDER BY T.std_age DESC)XCOL
FROM TABLE_1 AS T
)D
JOIN
(
select std_nm,
count(std_nm) as name_count,
sum(std_age) as sum_age,
avg(std_age) as avg_age
from TABLE_1
group by std_nm
)SUB_Q ON D.std_nm=SUB_Q.std_nm
Could you please try the above if it is suitable for you
CodePudding user response:
@Sergey's answer can be simplified by using Group Aggregates to avoid the join. This is a lot of cut&paste, but should result in a single step in Explain:
SELECT std_nm,std_age
,CASE
WHEN Row_Number() Over (PARTITION BY std_nm ORDER BY std_age DESC)=1
THEN Count(std_nm) Over (PARTITION BY std_nm )
END AS NAME_COUNT
,CASE
WHEN Row_Number() Over (PARTITION BY std_nm ORDER BY std_age DESC)=1
THEN Sum(std_age) Over (PARTITION BY std_nm )
END AS SUM_AGE
,CASE
WHEN Row_Number() Over (PARTITION BY std_nm ORDER BY std_age DESC)=1
THEN Avg(std_age) Over (PARTITION BY std_nm )
END AS AVG_AGE
FROM TABLE_1
;