I was unable to find this problem in the numerous Stack Overflow similar questions "how to read csv into a pyspark dataframe?" (see list of similar sounding but different questions at end).
The CSV file in question resides in the tmp directory of the driver of the cluster, note that this csv file is intentionally NOT in the Databricks DBFS cloud storage. Using DBFS will not work for the use case that led to this question.
Note I am trying to get this working on Databricks runtime 10.3 with Spark 3.2.1 and Scala 2.12.
y_header = ['fruit','color','size','note']
y = [('apple','red','medium','juicy')]
y.append(('grape','purple','small','fresh'))
import csv
with (open('/tmp/test.csv','w')) as f:
w = csv.writer(f)
w.writerow(y_header)
w.writerows(y)
Then use python os to verify the file was created:
import os
list(filter(lambda f: f == 'test.csv',os.listdir('/tmp/')))

Now verify that the databricks Spark API can see the file, have to use file:///
dbutils.fs.ls('file:///tmp/test.csv')

Now, optional step, specify a dataframe schema for Spark to apply to the csv file:
from pyspark.sql.types import *
csv_schema = StructType([StructField('fruit', StringType()), StructField('color', StringType()), StructField('size', StringType()), StructField('note', StringType())])
Now define the PySpark dataframe:
x = spark.read.csv('file:///tmp/test.csv',header=True,schema=csv_schema)
Above line runs no errors, but remember, due to lazy execution, the spark engine still has not read the file. So next we will give Spark a command that forces it to execute the dataframe:
display(x)
And the error is: FileReadException: Error while reading file file:/tmp/test.csv. It is possible the underlying files have been updated. You can explicitly invalidate the cache in Spark by running 'REFRESH TABLE tableName' command in SQL or by recreating the Dataset/DataFrame involved. If Delta cache is stale or the underlying files have been removed, you can invalidate Delta cache manually by restarting the cluster. Caused by: FileNotFoundException: File file:/tmp/test.csv does not exist. . .
and digging into the error I found this: java.io.FileNotFoundException: File file:/tmp/test.csv does not exist. And I already tried restarting the cluster, restart did not clear the error.
But I can prove the file does exist, only for some reason Spark and Java are unable to access it, because I can read in the same file with pandas no problem:
import pandas as p
p.read_csv('/tmp/test.csv')
So how do I get spark to read this csv file?
appendix - list of similar spark read csv questions I searched through that did not answer my question: 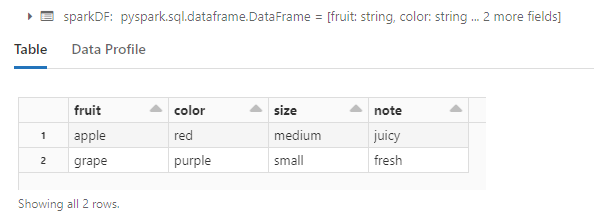
CodePudding user response:
I made email contact with a Databricks architect, who confirmed that Databricks can only read locally(from the cluster), in a single node setup.
So DBFS is the only option for random writing/reading of text data files.