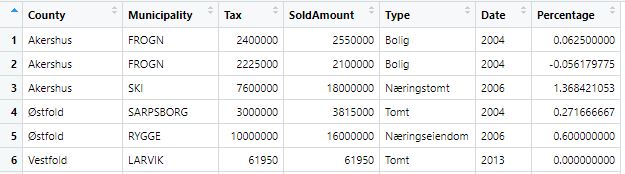
I would like to calculate the mean or median of one column, but be able to select which values are calculated based on another column. (see datatable below)
Calculating the mean/median of just the Percentage columns seems ok, but i am having some trouble when doing this based on other selections. For example the Percentage median of all entries where Date is "2014".
Any advice on how to do this is would be greatly appreciated! I appologize if this has been answered somwhere else here on SO but I was not able to find it.
My code is listed below if needed to reproduce the data.
#Step 1: Load needed library
library(tidyverse)
library(rvest)
library(jsonlite)
library(stringi)
library(dplyr)
library(data.table)
library(ggplot2)
#Step 2: Access the URL of where the data is located
url <- "https://www.forsvarsbygg.no/ListApi/ListContent/78635/SoldEstates/0/10/"
#Step 3: Direct JSON as format of data in URL
data <- jsonlite::fromJSON(url, flatten = TRUE)
#Step 4: Access all items in API
totalItems <- data$TotalNumberOfItems
#Step 5: Summarize all data from API
allData <- paste0('https://www.forsvarsbygg.no/ListApi/ListContent/78635/SoldEstates/0/', totalItems,'/') %>%
jsonlite::fromJSON(., flatten = TRUE) %>%
.[1] %>%
as.data.frame() %>%
rename_with(~str_replace(., "ListItems.", ""), everything())
#Step 6: removing colunms not needed
allData <- allData[, -c(1,4,8,9,11,12,13,14,15)]
#Step 7: remove whitespace and change to numeric in columns SoldAmount and Tax
#https://stackoverflow.com/questions/71440696/r-warning-argument-is-not-an-atomic-vector-when-attempting-to-remove-whites/71440806#71440806
allData[c("Tax", "SoldAmount")] <- lapply(allData[c("Tax", "SoldAmount")], function(z) as.numeric(gsub(" ", "", z)))
#Step 8: Remove rows where value is NA
#https://stackoverflow.com/questions/4862178/remove-rows-with-all-or-some-nas-missing-values-in-data-frame
alldata <- allData %>%
filter(across(where(is.numeric),
~ !is.na(.)))
#Step 9: Remove values below 10000 NOK on SoldAmount og Tax.
alldata <- alldata %>%
filter_all(any_vars(is.numeric(.) & . > 10000))
#Step 10: Calculate percentage change between tax and sold amount and create new column with percent change
#df %>% mutate(Percentage = number/sum(number))
alldata_Percent <- alldata %>% mutate(Percentage = (SoldAmount-Tax)/Tax)
CodePudding user response:
Are you just looking for group_by and summarize from dplyr?
alldata_Percent %>%
group_by(Date) %>%
summarize(median_percent = median(Percentage),
mean_percent = mean(Percentage))
## A tibble: 15 x 3
#> Date median_percent mean_percent
#> <chr> <dbl> <dbl>
#> 1 1970 0 1.98
#> 2 2003 0 -0.0345
#> 3 2004 0 0.141
#> 4 2005 0.0723 0.156
#> 5 2006 0.0132 0.204
#> 6 2007 0.024 0.131
#> 7 2008 0 -0.00499
#> 8 2009 0.0247 0.0769
#> 9 2010 0.0340 0.0422
#> 10 2011 0 0.155
#> 11 2012 0 0.0103
#> 12 2013 0 0.0571
#> 13 2014 0 0.0352
#> 14 2015 0 0.0646
#> 15 2016 0 -0.0195