I'm trying to figure out why Apple's Natural Language API returns unexpected results.
What am I doing wrong? Is it a grammar issue?
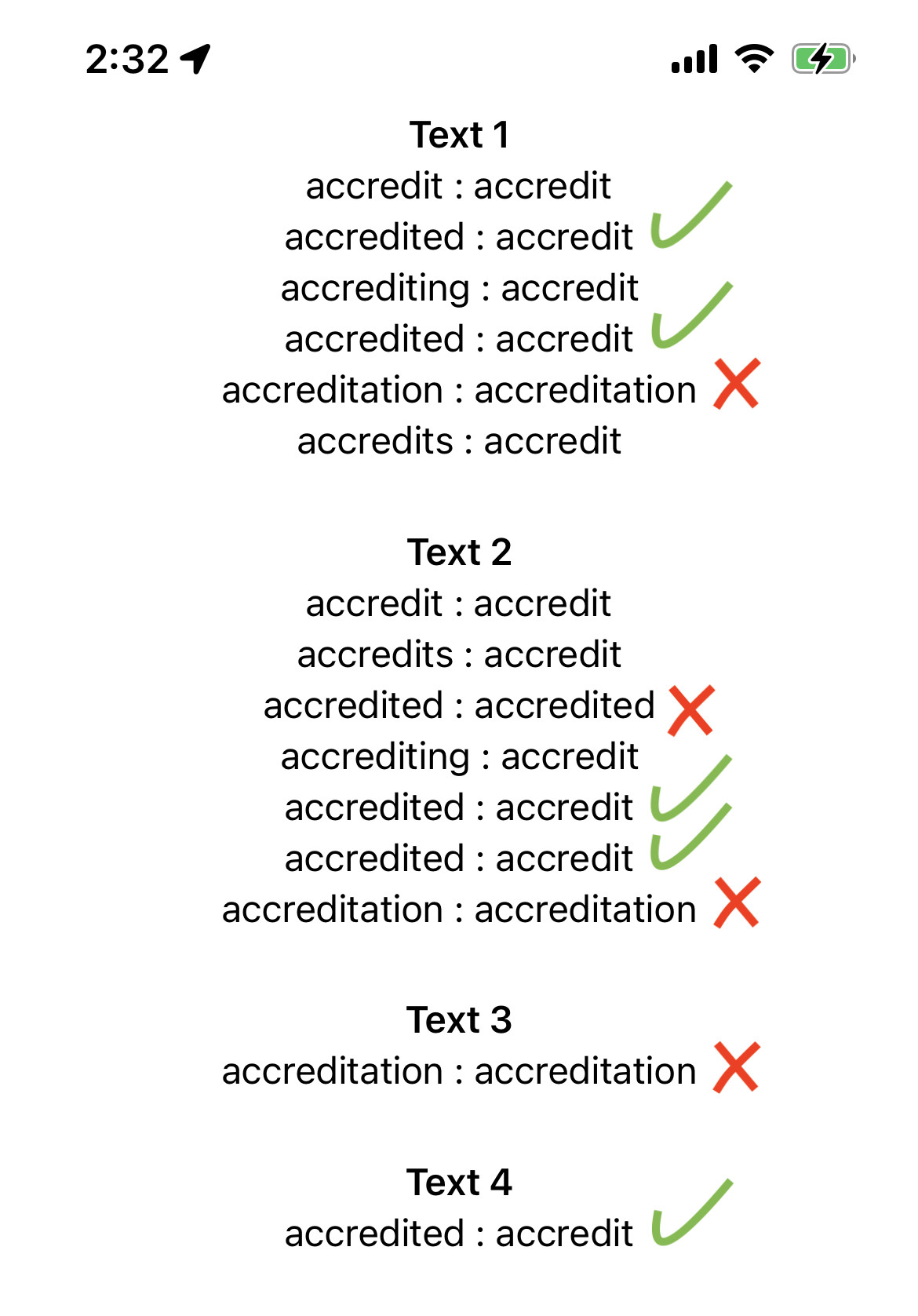
I have the following four strings, and I want to extract each word's "stem form."
// text 1 has two "accredited" in a different order
let text1: String = "accredit accredited accrediting accredited accreditation accredits"
// text 2 has three "accredited" in different order
let text2: String = "accredit accredits accredited accrediting accredited accredited accreditation"
// text 3 has "accreditation"
let text3: String = "accreditation"
// text 4 has "accredited"
let text4: String = "accredited"
The issue is with the words accreditation and accredited.
The word accreditation never returned the stem. And accredited returns different results based on the words' order in the string, as shown in Text 1 and Text 2 in the attached image.
I've used the code from Apple's documentation
And here is the full code in SwiftUI:
import SwiftUI
import NaturalLanguage
struct ContentView: View {
// text 1 has two "accredited" in a different order
let text1: String = "accredit accredited accrediting accredited accreditation accredits"
// text 2 has three "accredited" in a different order
let text2: String = "accredit accredits accredited accrediting accredited accredited accreditation"
// text 3 has "accreditation"
let text3: String = "accreditation"
// text 4 has "accredited"
let text4: String = "accredited"
var body: some View {
ScrollView {
VStack {
Text("Text 1").bold()
tagText(text: text1, scheme: .lemma).padding(.bottom)
Text("Text 2").bold()
tagText(text: text2, scheme: .lemma).padding(.bottom)
Text("Text 3").bold()
tagText(text: text3, scheme: .lemma).padding(.bottom)
Text("Text 4").bold()
tagText(text: text4, scheme: .lemma).padding(.bottom)
}
}
}
// MARK: - tagText
func tagText(text: String, scheme: NLTagScheme) -> some View {
VStack {
ForEach(partsOfSpeechTagger(for: text, scheme: scheme)) { word in
Text(word.description)
}
}
}
// MARK: - partsOfSpeechTagger
func partsOfSpeechTagger(for text: String, scheme: NLTagScheme) -> [NLPTagResult] {
var listOfTaggedWords: [NLPTagResult] = []
let tagger = NLTagger(tagSchemes: [scheme])
tagger.string = text
let range = text.startIndex..<text.endIndex
let options: NLTagger.Options = [.omitPunctuation, .omitWhitespace]
tagger.enumerateTags(in: range, unit: .word, scheme: scheme, options: options) { tag, tokenRange in
if let tag = tag {
let word: String = String(text[tokenRange])
let result = NLPTagResult(word: word, tag: tag)
//if !word.localizedCaseInsensitiveContains(tag.rawValue) {
listOfTaggedWords.append(result)
//}
}
return true
}
return listOfTaggedWords
}
// MARK: - NLPTagResult
struct NLPTagResult: Identifiable, Equatable, Hashable, Comparable {
var id = UUID()
var word: String
var tag: NLTag?
var description: String {
var newString: String = "\(word)"
if let tag = tag {
newString = " : \(tag.rawValue)"
}
return newString
}
// MARK: - Equatable & Hashable requirements
static func == (lhs: Self, rhs: Self) -> Bool {
lhs.id == rhs.id
}
func hash(into hasher: inout Hasher) {
hasher.combine(id)
}
// MARK: - Comparable requirements
static func <(lhs: NLPTagResult, rhs: NLPTagResult) -> Bool {
lhs.id.uuidString < rhs.id.uuidString
}
}
}
// MARK: - Previews
struct ContentView_Previews: PreviewProvider {
static var previews: some View {
ContentView()
}
}
Thanks for your help!
CodePudding user response:
As for why the tagger doesn't find "accredit" from "accreditation", this is because the scheme .lemma finds the lemma of words, not actually the stems. See the difference between stem and lemma on Wikipedia.
The stem is the part of the word that never changes even when morphologically inflected; a lemma is the base form of the word. For example, from "produced", the lemma is "produce", but the stem is "produc-". This is because there are words such as production and producing In linguistic analysis, the stem is defined more generally as the analyzed base form from which all inflected forms can be formed.
The documentation uses the word "stem", but I do think that the lemma is what is intended here, and getting "accreditation" is the expected behaviour. See the Usage section of the Wikipedia article for "Word stem" for more info. The lemma is the dictionary form of a word, and "accreditation" has a dictionary entry, whereas something like "accredited" doesn't. Whatever you call these things, the point is that there are two distinct concepts, and the tagger gets you one of them, but you are expecting the other one.
As for why the order of the words matters, this is because the tagger tries to analyse your words as "natural language", rather than each one individually. Naturally, word order matters. If you use .lexicalClass, you'll see that it thinks the third word in text2 is an adjective, which explains why it doesn't think its dictionary form is "accredit", because adjectives don't conjugate like that. Note that accredited is an adjective in the dictionary. So "is it a grammar issue?" Exactly.