I want to summarize the dataset based on "year", "months", and "subdist_id" columns. For each subdist_id, I want to get average values of "Rainfall" for the months 11,12,1,2 but for different years. For example, for subdist_id 81, the mean Rainfall value of 2004 will be the mean Rainfall of months 11, 12 of 2004, and months 1,2 of 2005.
I am getting no clue how to do it, although I searched online rigorously.
CodePudding user response:
Expanding on @Bloxx's answer and incorporating my comment:
# Set up example data frame:
df = data.frame(year=c(rep.int(2004,2),rep.int(2005,4)),
month=((0:5%%4)-2)% 1,
Rainfall=seq(.5,by=0.15,length.out=6))
Now use mutate to create year2 variable:
df %>% mutate(year2 = year - (month<3)*1) # or similar depending on the problem specs
And now apply the groupby/summarise action:
df %>% mutate(year2 = year - (month<3)*1) %>%
group_by(year2) %>%
summarise(Rainfall = mean(Rainfall))
CodePudding user response:
Lets assume your dataset is called df. Is this what you are looking for?
df %>% group_by(subdist_id, year) %>% summarise(Rainfall = mean(Rainfall))
CodePudding user response:
I think you can simply do this:
df %>% filter(months %in% c(1,2,11,12)) %>%
group_by(subdist_id, year=if_else(months %in% c(1,2),year-1,year)) %>%
summarize(meanRain = mean(Rainfall))
Output:
subdist_id year meanRain
<dbl> <dbl> <dbl>
1 81 2004 0.611
2 81 2005 0.228
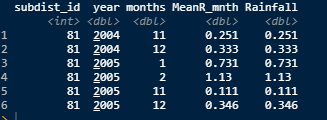
Input:
df = data.frame(
subdist_id = 81,
year=c(2004,2004, 2005, 2005, 2005, 2005),
months=c(11,12,1,2,11,12),
Rainfall = c(.251,.333,.731,1.13,.111,.346)
)