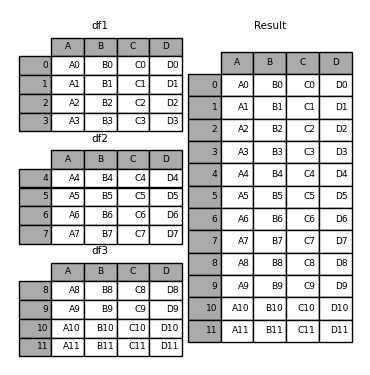
Can someone please tell me how I can achieve results like the image above, but with the following differences:
# Note the column names
df1 = pd.DataFrame({"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
},
index = [0, 1, 2, 3],
)
# Note the column names
df2 = pd.DataFrame({"AA": ["A4", "A5", "A6", "A7"],
"BB": ["B4", "B5", "B6", "B7"],
"CC": ["C4", "C5", "C6", "C7"],
"DD": ["D4", "D5", "D6", "D7"],
},
index = [4, 5, 6, 7],
)
# Note the column names
df3 = pd.DataFrame({"AAA": ["A8", "A9", "A10", "A11"],
"BBB": ["B8", "B9", "B10", "B11"],
"CCC": ["C8", "C9", "C10", "C11"],
"DDD": ["D8", "D9", "D10", "D11"],
},
index = [8, 9, 10, 11],
)
Every kind of merge I do results in this:
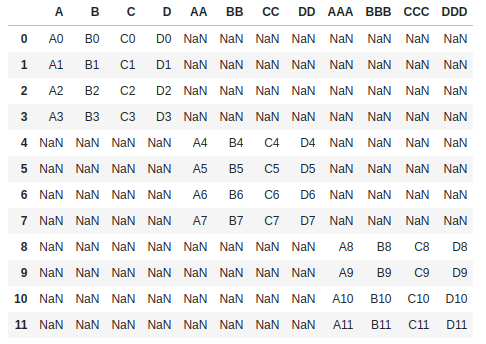
Here's what I'm trying to accomplish:
- I'm doing my Capstone Project, and the use case uses the
SpaceXdata set. I've web-scraped the tables found here: SpaceX Falcon 9 Wikipedia,
Now I'm trying to combine them into one large table. However, there are slight differences in the column names, between each table, and so I have to do more logic to merge properly. There are 10 tables in total, I've checked 5. 3 have unique column names, so the simple merging doesn't work.
I've searched around at the other questions, but the use case is different than mine, so I haven't found an answer that works for me.
I'd really appreciate someone's help, or pointing me where I can find more info on the subject. So far I've had no luck in my searches.
CodePudding user response:
Let us just do np.concatenate
out = pd.DataFrame(np.concatenate([df1.values,df2.values,df3.values]),columns=df1.columns)
Out[346]:
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
8 A8 B8 C8 D8
9 A9 B9 C9 D9
10 A10 B10 C10 D10
11 A11 B11 C11 D11
CodePudding user response:
IIUC, you could just modify the column names and concatenate:
df2.columns = df2.columns.str[0]
df3.columns = df3.columns.str[0]
out = pd.concat([df1, df2, df3])
or if you're into one-liners, you could do:
out = pd.concat([df1, df2.rename(columns=lambda x:x[0]), df3.rename(columns=lambda x:x[0])])
Output:
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
8 A8 B8 C8 D8
9 A9 B9 C9 D9
10 A10 B10 C10 D10
11 A11 B11 C11 D11