I have a daframe with several columns but some of them starts with test_
Below a sample with ONLY these test_ columns:
c = pd.DataFrame({'test_pierce':[10,30,40,50],'test_failure':[30,10,20,10] })
What I need to do:
For every column in my dataframe that starts with test_ I want to create another column just after to classify it's value like this:
if test_ > 30.0:
Y
else:
N
To get this output:
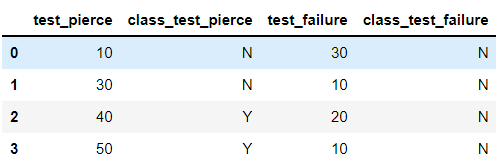
d = pd.DataFrame({'test_pierce':[10,30,40,50],'class_test_pierce':['N','N','Y','Y'],'test_failure':[30,10,20,10], 'class_test_failure':['N','N','N','N'] })
What I did:
I have the columns I need to classify:
cols = [c for c in c.columns if c.startswith('test_')]
I couldn't proceed from here tho
CodePudding user response:
Code with the suggested order:
The code is a little ugly because you asked to be the columns after its test_ column. Otherwise, the code is simpler than that.
cols = [(i,c) for i,c in enumerate(c.columns) if c.startswith('test_')]
count = 1
for index,col in cols:
value = np.where(c[col] > 30.0,'Y','N')
c.insert(index count, 'class_' col, value)
count =1
Code without the suggested order:
cols = [c for c in c.columns if c.startswith('test_')]
for col in cols:
c[f'class_{col}'] = np.where(c[col] > 30.0,'Y','N')
CodePudding user response:
A format that may help you get started is:
cols = [c for c in c.columns if c.startswith('test_')]
for col in cols:
df[f'class_{col}'] = df.apply(lambda x: 'Y' if x[col] > 30.0 else 'N', axis=1)
Output:
test_pierce test_failure class_test_pierce class_test_failure
0 10 30 N N
1 30 10 N N
2 40 20 Y N
3 50 10 Y N