I have the following dataframe:
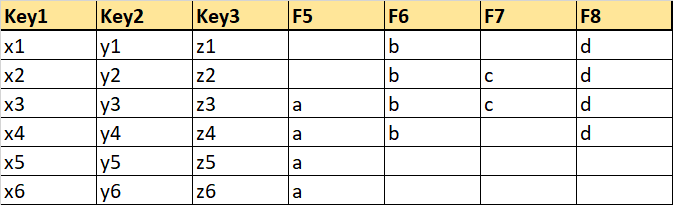
I want to output the data into multiple sheets that will contain partial filled fields.
Partial Sheet 1:
First 3 are the key columns. I want to compare the columns F5,F6,F7,F8 and get the columns which have data in the same index and delete the rest. There can be N number of columns.
In this case, my output should be in the following format:
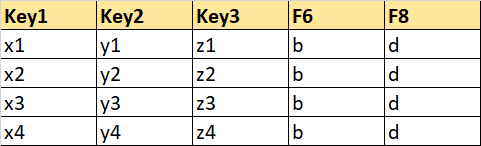
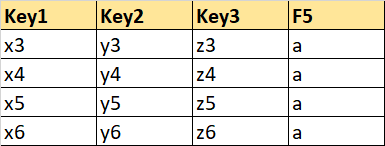
Partial Sheet 2: Will contains Key columns and one field column (F5) without null values.
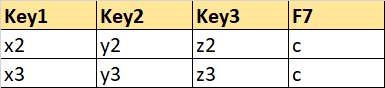
Partial Sheet 3: Will contains Key columns and one field column (F7) without null values.
I tried researching a lot however could not find anything substantial.
Any ideas would be appreciated.
CodePudding user response:
Use:
#if missing values are not NaNs
df = df.replace('', np.nan)
#columns from third column
cols = df.columns[3:]
#columns with keys
keycols = df.columns[:3].tolist()
out = cols.copy()
df1 = df.copy()
#in loop create combinations of columns with same index
final_cols = []
for c in out:
if c in out:
m = df1[c].notna()
#test if all columns has not missing values like tested column
#and also test if rows with missing values like tested column are missed too
c1=out[df.loc[m, out].notna().all()].intersection(out[df.loc[~m, out].isna().all()])
df1 = df1.drop(c1, axis=1)
out = out.difference(c1)
final_cols.append(c1.tolist())
#finally sorted list of columns by length
final_cols = sorted(final_cols, key=len, reverse=True)
#create excel with multiple sheets
with pd.ExcelWriter('output.xlsx', engine='xlsxwriter') as writer:
for c in final_cols:
df[keycols c].dropna(subset=c).to_excel(writer, sheet_name=f'{"_".join(c)}')
CodePudding user response:
Full code
cols = df.filter(like='F').replace('', pd.NA).stack().reset_index(0).groupby(level=0)['level_0'].agg(frozenset)
common = cols.reset_index().groupby('level_0')['index'].agg(list).to_list()
extra = ['Key1', 'Key2', 'Key3']
for c in common:
print(f'data_cols_{"-".join(c)}.csv')
print(df.loc[cols[c[0]], extra c])
Details
step1
You can first use aggregation as frozensets to identify the non-NA indices per column:
cols = (df
.filter(like='F').replace('', pd.NA)
.stack().reset_index(0)
.groupby(level=0)['level_0'].agg(frozenset)
)
output:
F5 (2, 3, 4, 5)
F6 (0, 1, 2, 3)
F7 (1, 2)
F8 (0, 1, 2, 3)
Name: level_0, dtype: object
step2
Then aggregate again to group the columns with the same indices:
common = cols.reset_index().groupby('level_0')['index'].agg(list).to_list()
# [['F5'], ['F7'], ['F6', 'F8']]
step3
Finally, slice and export:
extra = ['Key1', 'Key2', 'Key3']
for c in common:
print(f'data_cols_{"-".join(c)}.csv')
df.loc[cols[c[0]], extra c].to_csv(f'data_cols_{"-".join(c)}.csv')
output:
data_cols_F5.csv
Key1 Key2 Key3 F5
2 x3 y3 z3 a
3 x4 y4 z4 a
4 x5 y5 z5 a
5 x6 y6 z6 a
data_cols_F7.csv
Key1 Key2 Key3 F7
1 x2 y2 z2 c
2 x3 y3 z3 c
data_cols_F6-F8.csv
Key1 Key2 Key3 F6 F8
0 x1 y1 z1 b d
1 x2 y2 z2 b d
2 x3 y3 z3 b d
3 x4 y4 z4 b d
used input
df = pd.DataFrame({'Key1': ['x1', 'x2', 'x3', 'x4', 'x5', 'x6'],
'Key2': ['y1', 'y2', 'y3', 'y4', 'y5', 'y6'],
'Key3': ['z1', 'z2', 'z3', 'z4', 'z5', 'z6'],
'F5': ['', '', 'a', 'a', 'a', 'a'],
'F6': ['b', 'b', 'b', 'b', '', ''],
'F7': ['', 'c', 'c', '', '', ''],
'F8': ['d', 'd', 'd', 'd', '', '']})
comparison of the different answers:
on 60k rows
# mozway
69.3 ms ± 7.79 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
# jezrael
122 ms ± 9.87 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
on 600k rows:
# mozway
747 ms ± 69.4 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
# jezrael
1.32 s ± 61.5 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)