I have a DataFrame by pandas, and it contains a lots of NaN values.
the following figure is about data what I have,
| 2ndFlrSF | SalePrice | |
|---|---|---|
| 0 | 854 | 208500 |
| 1 | 0 | 181500 |
| 2 | 866 | 223500 |
| 3 | 756 | 140000 |
| 4 | 1053 | 250000 |
| ... | ... | ... |
| 1455 | 694 | 175000 |
| 1456 | 0 | 210000 |
| 1457 | 1152 | 266500 |
| 1458 | 0 | 142125 |
| 1459 | 0 | 147500 |
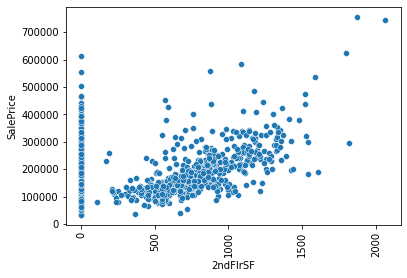
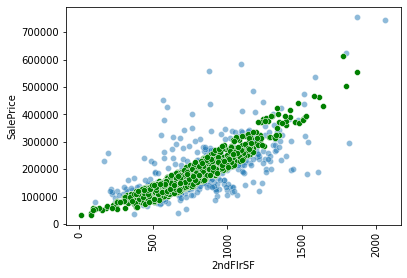
and next one is what I expected.
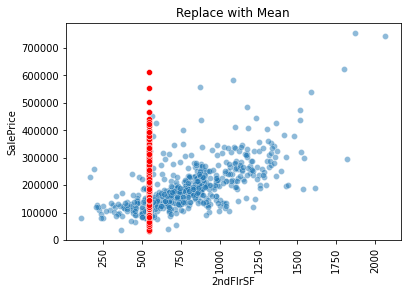
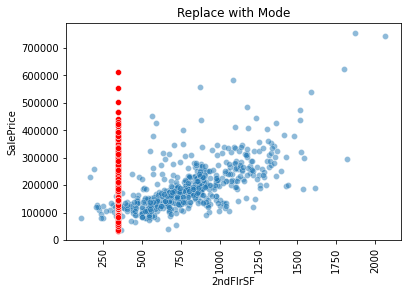
I have tried to fill NaN values with average(mean) and most frequents, but it is not what i want to.
Is there any package or method to fill the values with scaled for this?
one thing I would like to comment is, I do NOT want to drop this values.
if any solution, please let me know. thanks.
EDITED:
I found 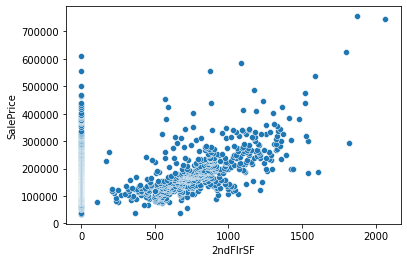
After interpolate values with SalePrice
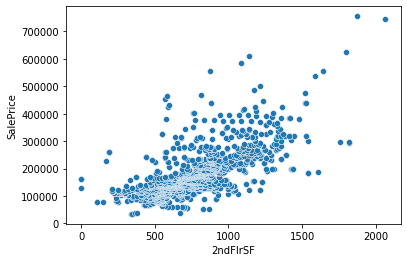
I uploaded code and sample data.
you can see sample data and its result from: https://gist.github.com/joonas-yoon/f5d01db4470ff87e442dc01c99f04c47#file-sample-txt
Thanks for all of comments and replies.