I have a dataframe that looks like this:
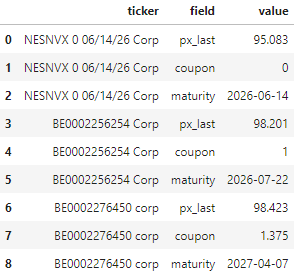
Here is the text of the same image (for convenience):
ticker field value
0 NESNVX 0 06/14/26 Corp px_last 95.083
1 NESNVX 0 06/14/26 Corp coupon 0
2 NESNVX 0 06/14/26 Corp maturity 2026-06-14
3 BE0002256254 Corp px_last 98.201
4 BE0002256254 Corp coupon 1
5 BE0002256254 Corp maturity 2026-07-22
6 BE0002276450 corp px_last 98.423
7 BE0002276450 corp coupon 1.375
8 BE0002276450 corp maturity 2027-04-07
The ticker column is repeated by n fields. So, for example, if there are 3 unique field items, the ticker is repeated 3 times (as in the example above).
How do i transform this to a grid such that it is just tickers (as index) vs fields (as the column headers) with the value as the elements of the matrix ?
I have tried to use the groupby function, but cannot seem to get this to work the way i need it to.
The result that i seek, would be this:
ticker px_last coupon maturity
0 NESNVX 0 06/14/26 Corp 95.083 0 2026-06-14
1 BE0002256254 Corp 98.201 1 2026-07-22
2 BE0002276450 corp 98.423 1.375 2027-04-07
CodePudding user response:
one of the way is to create another dictionary to fit what you need in this case : suppose that df is your initial database
Dict=dict()
Dict['ticker']=[]
for n in range(len(df)//3):
Dict['ticker'].append(df.loc[3*n][0])
Dict[df.loc[n][1]]=[]
for n in range(len(df)):
Dict[df.loc[n%3][1]].append(df.loc[n][2])
df2=pd.DataFrame(Dict)
CodePudding user response:
pandas.pivot might be what you are looking for.
df = pd.DataFrame({
'ticker': [
'NESNVX 0 06/14/26 Corp',
'NESNVX 0 06/14/26 Corp',
'NESNVX 0 06/14/26 Corp',
'BE0002256254 Corp',
'BE0002256254 Corp',
'BE0002256254 Corp',
'BE0002276450 corp',
'BE0002276450 corp',
'BE0002276450 corp'
],
'field': ['px_last', 'coupon', 'maturity', 'px_last', 'coupon', 'maturity', 'px_last', 'coupon', 'maturity'],
'value': [95.083, 0, '2026-06-14', 98.201, 1, '2026-07-22', 98.423, 1.375, '2027-04-07']
})
result = df.pivot(index='ticker', columns='field', values='value')
This creates dataframe with field column as index, to use integer index and set field as a column, you can use:
result.reset_index(inplace=True)
Result:
field ticker coupon maturity px_last
0 BE0002256254 Corp 1 2026-07-22 98.201
1 BE0002276450 corp 1.375 2027-04-07 98.423
2 NESNVX 0 06/14/26 Corp 0 2026-06-14 95.083