When I try to use apply() function to add the new column based on another column, there is an error. I do not what's going on here?
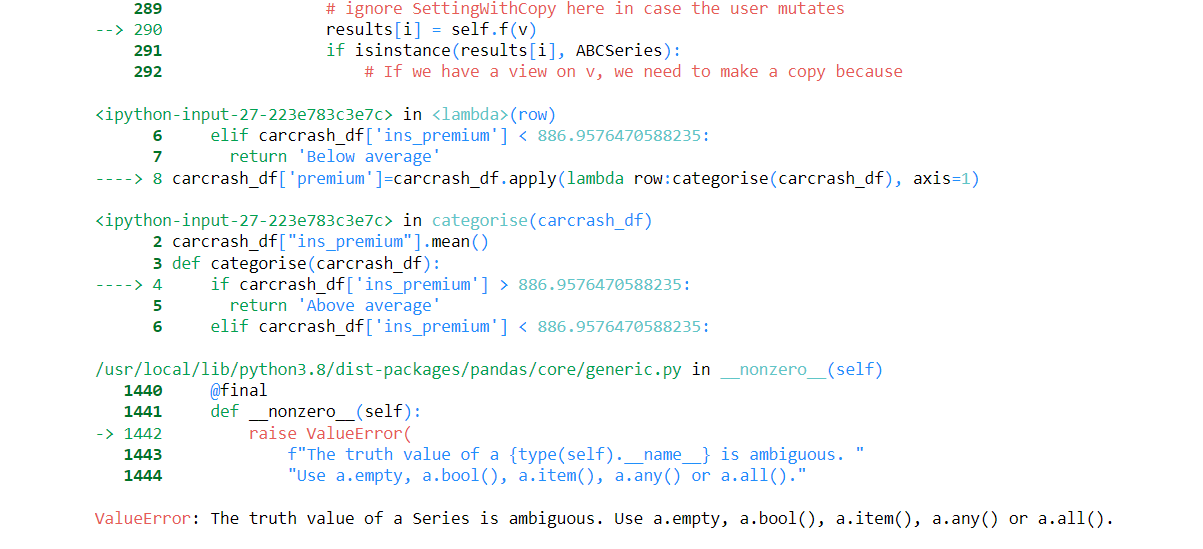
carcrash_data = sns.load_dataset('car_crashes')
carcrash_df = pd.DataFrame(carcrash_data)
carcrash_df["ins_premium"].mean()
def categorise(carcrash_df):
if carcrash_df['ins_premium'] > 886.9576470588235:
return 'Above average'
elif carcrash_df['ins_premium'] < 886.9576470588235:
return 'Below average'
carcrash_df['premium']=carcrash_df.apply(lambda row:categorise(carcrash_df), axis=1)
CodePudding user response:
In your apply function you take row, I believe you should pass it as an argument to your function as well. See the code below.
carcrash_data = sns.load_dataset('car_crashes')
carcrash_df = pd.DataFrame(carcrash_data)
carcrash_df["ins_premium"].mean()
def categorise(row):
if row['ins_premium'] > 886.9576470588235:
return 'Above average'
elif row['ins_premium'] < 886.9576470588235:
return 'Below average'
carcrash_df['premium']=carcrash_df.apply(lambda row:categorise(row), axis=1)