Using databricks with SQL, I have to import my csv dataset into a table and analyse data using it. My problem is after I imported csv dataset, all column are String type, but some of these need to be Numeric. How can I solve?
How can I define the column types of a csv file? I tried converting file in xlsx and setting numeric type but then it's not possible to convert again in csv (or I don't know how).
Thanks for helping
PS: databricks wants just csv file and not xlsx or similar.
CodePudding user response:
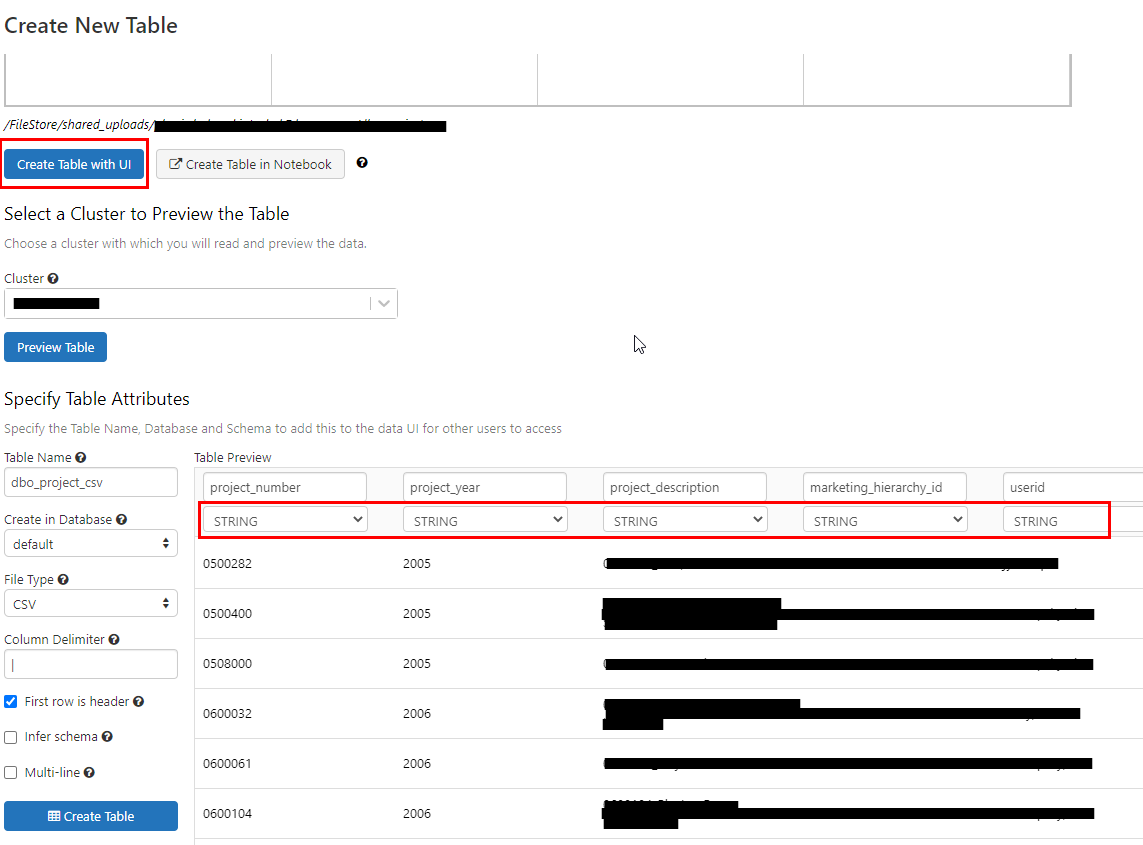
If you are using Databricks on Azure, when you select "Create table with UI" there should be options for you to choose a data type for each column as in the screenshot A below.
If you are importing table by some Python Spark codes, there should be an option, infer_schema, for you to set. If it is set to "true", all columns that contain only numeric will have appropriate numeric data types.
file_location = "/FileStore/shared_uploads/xxx/dbo_project.csv"
file_type = "csv"
infer_schema = "true"
first_row_is_header = "false"
delimiter = ","
df = spark.read.format(file_type) \
.option("inferSchema", infer_schema) \
.option("header", first_row_is_header) \
.option("sep", delimiter) \
.load(file_location)
Screenshot A