I have a dataframe with the following structure:
import numpy as np
import pandas as pd
df = pd.DataFrame(
{
"date": ["2020-01-01", "2020-01-02", "2020-01-03", "2020-01-04"] * 2,
"group": ["A", "A", "A", "A", "B", "B", "B", "B"],
"x": [1, 2, 2, 3, 2, 3, 4, 2],
"condition": [1, 0, 1, 0] * 2
}
)
df
I want to calculate, the rolling moving average of the last 3 days of the column x:
- Per group
- Using only past data (not using the current row)
- Using only data for the rolling average where
condition = 1.
The outcome should be the following:
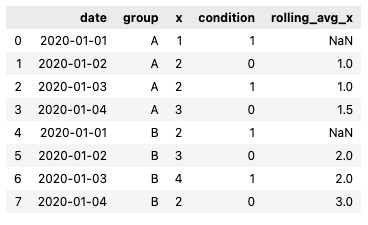
How can I do that in pandas? Thanks!
Keep in mind it is not the same as this:
Rolling function in pandas with condition
In here I'm looking for the moving average of the last 3 days, in the other one I just wanted the rolling average.
CodePudding user response:
First replace not matched rows by NaN by Series.where and then per groups shift values and call rolling method:
f = lambda x: x.shift().rolling(3, min_periods=1).mean()
df['roll'] = (df.assign(x = df['x'].where(df['condition'].eq(1)))
.groupby('group')['x']
.transform(f))
print (df)
date group x condition roll
0 2020-01-01 A 1 1 NaN
1 2020-01-02 A 2 0 1.0
2 2020-01-03 A 2 1 1.0
3 2020-01-04 A 3 0 1.5
4 2020-01-01 B 2 1 NaN
5 2020-01-02 B 3 0 2.0
6 2020-01-03 B 4 1 2.0
7 2020-01-04 B 2 0 3.0
Details:
print (df.assign(x = df['x'].where(df['condition'].eq(1))))
date group x condition
0 2020-01-01 A 1.0 1
1 2020-01-02 A NaN 0
2 2020-01-03 A 2.0 1
3 2020-01-04 A NaN 0
4 2020-01-01 B 2.0 1
5 2020-01-02 B NaN 0
6 2020-01-03 B 4.0 1
7 2020-01-04 B NaN 0