I have a dataframe with the following structure:
import numpy as np
import pandas as pd
df = pd.DataFrame(
{
"date": ["2020-01-01", "2020-01-02", "2020-01-03", "2020-01-04"] * 2,
"group": ["A", "A", "A", "A", "B", "B", "B", "B"],
"x": [1, 2, 2, 3, 2, 3, 4, 2],
"condition": [1, 0, 1, 0] * 2
}
)
df
I want to calculate, the rolling average of the column x:
- Per group
- Using only past data (not using the current row)
- Using only data for the rolling average where
condition = 1.
The outcome should be the following:
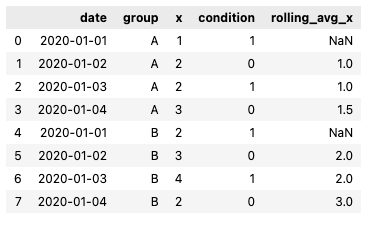
How can I do that in pandas? Thanks!
CodePudding user response:
I think we should filter the dataframe on conditions and then calculate the mean of x
- group == group of current row
- date < date of current row
- condition == 1
df.apply is used to apply to all rows of the dataframe
df['rolling_avg_x'] = df.apply(lambda x: df[(df.group == x.group) & (df.date < x.date) & (df.condition == 1)].x.mean(), axis=1)
This will give you the output as desire